Por qué leer este artículo
Tres razones operativas para leer, evaluar y enseñar comprensión en la era de la IA.
En la era de la IA, la competencia clave es “auditar” textos
Un texto puede sonar científico y estar vacío o sesgado. Aquí se explican criterios para evaluar consistencia, evidencia y trazabilidad en outputs humanos y generados.
Un modelo claro para comprender y enseñar comprensión
La anatomía del texto (micro–macro–superestructura) se vuelve una herramienta didáctica y de investigación para mejorar comprensión, síntesis, escritura académica y evaluación.
Lectura e IA, de forma operativa (sin humo)
Traduce memoria y significado a prácticas concretas: búsqueda semántica, embeddings y RAG como “memorias externas” para investigar, diseñar actividades y reducir alucinaciones con verificación.
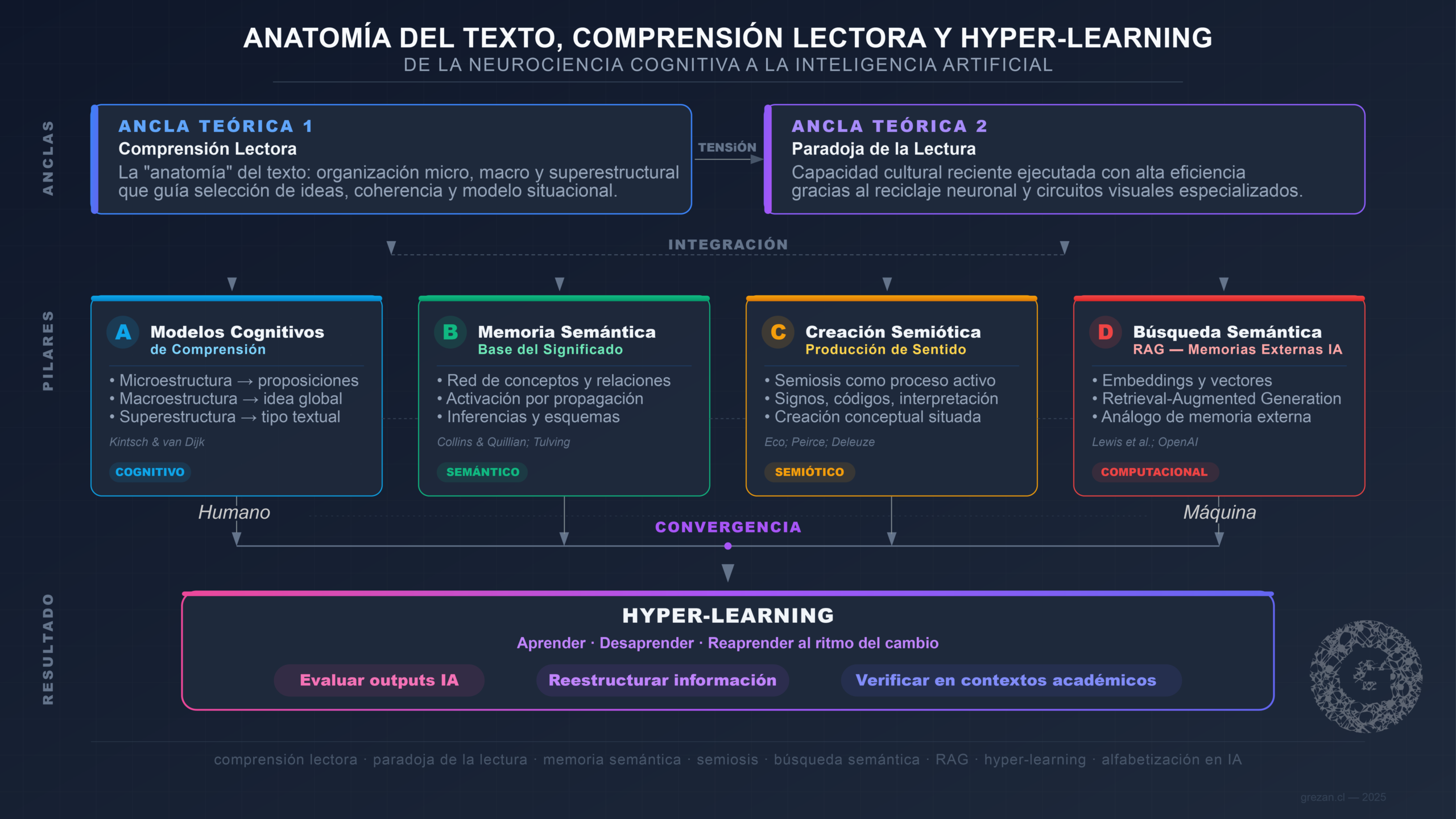
La comprensión lectora depende en gran medida de la “anatomía” del texto: la organización microestructural, macroestructural y superestructural que guía la selección de ideas, la construcción de coherencia y el ensamblaje de un modelo situacional. Desde la neurociencia cognitiva, la lectura presenta una tensión central conocida como “paradoja de la lectura”: una capacidad cultural reciente que, sin embargo, se ejecuta con alta eficiencia gracias al reciclaje neuronal y a circuitos visuales especializados para el reconocimiento ortográfico. Este artículo integra (a) modelos cognitivos de comprensión, (b) la memoria semántica como base del significado, (c) la creación semiótica y conceptual como operación de producción de sentido, y (d) la búsqueda semántica y la generación aumentada por recuperación (RAG) como análogos técnico-computacionales de “memorias externas” para la IA. Finalmente, se propone que el hyper-learning —aprender, desaprender y reaprender al ritmo del cambio— requiere competencias textuales avanzadas para evaluar, reestructurar y verificar outputs de IA en contextos académicos y profesionales.
Palabras clave: comprensión lectora; paradoja de la lectura; memoria semántica; semiosis; búsqueda semántica; RAG; hyper-learning; alfabetización en IA.
1. Introducción
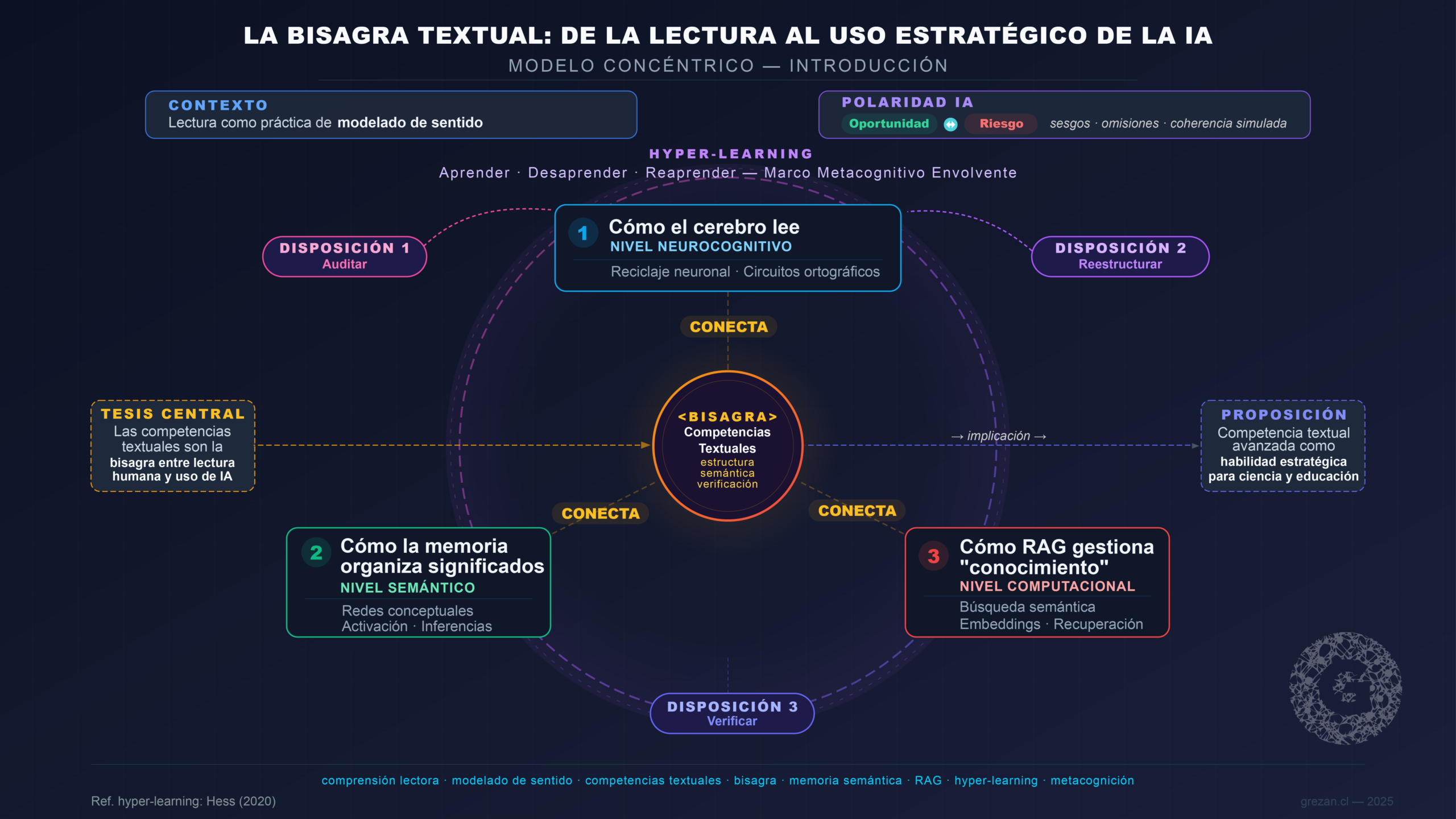
En entornos saturados por información y sistemas generativos, la lectura ya no es solo acceso a contenido: es una práctica de modelado de sentido. Este modelado depende de la estructura interna del texto (su “anatomía”), que permite transformar secuencias de signos en inferencias, explicaciones y decisiones. En paralelo, los sistemas de IA contemporáneos producen textos plausibles y altamente estructurados, lo cual crea una oportunidad y un riesgo: pueden acelerar la síntesis, pero también estabilizar sesgos, omitir evidencias o simular coherencia sin sustento.
Este artículo sostiene una tesis central: las competencias textuales (estructura, semántica, verificación) son la bisagra entre la lectura humana y el uso estratégico de la IA, porque conectan tres niveles: (1) cómo el cerebro lee, (2) cómo la memoria organiza significados, y (3) cómo las infraestructuras de búsqueda semántica y recuperación (p. ej., RAG) gestionan “conocimiento” para la generación. El concepto de hyper-learning (Hess, 2020) —aprender, desaprender y reaprender de manera continua y colaborativa— opera como marco de acción que articula estos niveles: no basta con leer ni con usar IA; es necesario desarrollar una disposición metacognitiva que permita auditar, reestructurar y verificar tanto los propios modelos mentales como los productos textuales generados por sistemas automatizados.
La estructura del texto avanza desde la base neurocognitiva de la lectura hacia sus implicaciones para la educación y la investigación mediadas por IA, proponiendo que la competencia textual avanzada constituye hoy una habilidad estratégica para la ciencia y la educación contemporánea.
2. La paradoja de la lectura y el cerebro lector
La lectura es una invención cultural relativamente reciente; no hubo tiempo evolutivo suficiente para que apareciera un “órgano de lectura” dedicado. Aun así, los lectores expertos muestran patrones reproducibles de activación cerebral durante el reconocimiento de palabras, fenómeno resumido por Dehaene como la “paradoja de la lectura”: una capacidad moderna soportada por circuitos más antiguos, reorganizados por aprendizaje (Dehaene, s. f.). Esta explicación se vincula con la hipótesis del reciclaje neuronal, donde regiones visuales se especializan para procesar cadenas ortográficas (Dehaene et al., 2011).
En términos funcionales, la lectura se apoya en un procesamiento jerárquico: desde rasgos visuales hacia patrones de letras y finalmente hacia interfaces con sonido y significado. Parte de esta arquitectura se asocia a la denominada Visual Word Form Area (VWFA), región del sistema visual ventral que se vuelve selectiva para palabras y cadenas de letras en lectores alfabetizados (Dehaene et al., 2011; MIT BCS, 2019).
2.1 Nuevas evidencias: de la competencia al surgimiento
Investigaciones recientes han complejizado este panorama. Kubota et al. (2024), en una revisión de datos longitudinales de neuroimagen en desarrollo, proponen que las regiones selectivas a palabras no se instalan “reciclando” corteza previamente dedicada a rostros, como sugería la formulación original de Dehaene y Cohen, sino que emergen a partir de territorio cortical débilmente especializado. Su modelo de “surgimiento” (emergence) reformula la paradoja: el cerebro no resuelve el problema por competencia entre funciones, sino generando nuevas representaciones categoriales en zonas con baja selectividad previa.
Esta perspectiva recibe respaldo experimental directo. Yeatman et al. (2024) condujeron el primer ensayo controlado aleatorio que mide el impacto causal de la instrucción en lectura sobre la organización de la corteza visual en niños preescolares mediante magnetoencefalografía. La instrucción modificó las respuestas selectivas de categoría en la región de la VWFA, pero —contrariamente a la predicción estricta del reciclaje neuronal— no produjo una reducción compensatoria en las respuestas a rostros u objetos. Por su parte, Chyl et al. (2023), en un estudio con 72 niños de seis años previo a la alfabetización formal, encontraron que solo los estímulos de texto impreso (no rostros, casas ni falsas fuentes) activaban una red amplia de áreas lingüísticas, lo que sugiere que el cerebro pre-lector ya contiene precondiciones arquitectónicas que permiten acomodar el lenguaje escrito sin desplazar funciones previas.
2.2 Subregiones de la VWFA y el puente visión-lenguaje
La VWFA no es una unidad monolítica. Yablonski et al. (2024), usando datos de fMRI a 7T en adultos y una muestra longitudinal de 224 participantes de 6 a 20 años, identificaron al menos dos subregiones funcionales: una VWFA-1 posterior, conectada bilateralmente con áreas visuales, y una VWFA-2 anterior, con conectividad robusta hacia regiones frontales del lenguaje. Este gradiente posterior-anterior constituye la solución arquitectónica que el cerebro despliega para vincular percepción visual y procesamiento lingüístico. Li et al. (2024), mediante fMRI de precisión con datos extensos por sujeto, confirman que la VWFA funciona como un “diccionario ortográfico visual” que, además, participa en el procesamiento del lenguaje auditivo: la única región selectiva de categoría en la corteza temporal ventral con esta doble función. Adicionalmente, Chauhan et al. (2024) demostraron que la selectividad de la VWFA es moldeada tanto por características sensoriales ascendentes como por demandas descendentes de la tarea, mostrando que la selectividad específica de la alfabetización emerge incluso bajo condiciones de visualización pasiva.
Dębska et al. (2023) ofrecen una revisión comprehensiva que traza la evolución desde un modelo de “buzón de letras” estrictamente visual hacia un hub de integración lingüística independiente de modalidad. Y el caso extremo lo aportan Seydell-Greenwald et al. (2025): en individuos con dominancia lingüística hemisférica derecha tras un accidente cerebrovascular perinatal izquierdo, la VWFA se desarrolló en el giro fusiforme derecho, pese a que la corteza izquierda estaba intacta. El sustrato neural de la lectura no está programado: emerge a través de la conectividad con el sistema lingüístico, y puede relocalizarse completamente si las condiciones lo requieren.
La Paradoja de la Lectura y el Cerebro Lector
Sección 2 — Explora el cambio de paradigma
¿Cómo resuelve el cerebro la paradoja de leer?
La lectura es una invención de ~5.000 años — demasiado reciente para la evolución. Dos modelos compiten por explicar cómo el cerebro la hace posible.
Reciclaje Neuronal
Surgimiento
⟡ Implicación del cambio de paradigma
De reciclaje competitivo a surgimiento cooperativo: leer no es conquistar territorio neural ajeno, sino cultivar nuevas representaciones sobre plasticidad dependiente de la experiencia.
Arquitectura VWFA: El Puente Visión-Lenguaje
La Visual Word Form Area no es monolítica. Explora el gradiente funcional y sus conexiones.
VWFA-1 Posterior
Conectividad bilateral con áreas visuales. Procesa propiedades perceptuales de cadenas de letras — nivel ortográfico-visual.
VWFA-2 Anterior
Conectividad frontal-lingüística (Broca). Puente donde la forma se convierte en significado.
Diccionario + Auditivo
"Diccionario ortográfico visual" que participa en lenguaje auditivo — única región de categoría en corteza temporal ventral con doble función.
Relocalización total
Tras ACV perinatal izquierdo, la VWFA se desarrolló en hemisferio derecho. No está preprogramada: emerge por conectividad lingüística.
⟡ De buzón de letras a hub de integración
La VWFA pasó de módulo visual a hub lingüístico independiente de modalidad, moldeado por señales ascendentes y descendentes (Chauhan et al., 2024). La lectura es un acto de integración multinivel.
Mapa de Evidencia: 8 Estudios Clave
Cada estudio aporta una pieza al rompecabezas. Haz clic para explorar hallazgo y contribución.
⟡ Convergencia
8 estudios, una reinterpretación: la lectura construye sentido sobre una base que automatiza reconocimiento mediante plasticidad — no competencia destructiva — para que la cognición se dedique a integrar, evaluar y decidir.
paradoja de la lectura · reciclaje neuronal · surgimiento · VWFA · plasticidad · hyper-learning
3. Anatomía del texto y modelos de comprensión: de la microestructura al modelo situacional
Los modelos cognitivos de comprensión describen la lectura como construcción progresiva de representaciones. En el enfoque de van Dijk y Kintsch (1983), el lector elabora una base textual y una macroestructura mediante reglas de reducción y jerarquización de información. Kintsch (1988) profundiza este proceso con el modelo Construcción–Integración (CI), donde el significado emerge al activar proposiciones y conocimiento previo y luego “depurar” la red mediante restricciones de coherencia.
En este marco, la anatomía textual opera en tres planos: la microestructura (cohesión local, conectores y relaciones proposicionales), la macroestructura (organización global y extracción de ideas principales) y la superestructura (patrón del género —expositivo, argumentativo, narrativo— que activa expectativas sobre tesis, evidencias, secuencias o problemas-soluciones).
3.1 La vigencia del modelo: el número especial en honor a Kintsch (2024)
La relevancia contemporánea de este marco se evidencia en el número especial de Discourse Processes (Vol. 61, Nos. 6–7, 2024), con 18 comentarios de investigadores de referencia en honor a Walter Kintsch (1932–2023). McNamara et al. (2024), en la introducción editorial, trazan el impacto de Kintsch desde el modelo proposicional hasta el Análisis Semántico Latente y sus conexiones con los actuales modelos de lenguaje de gran escala, subrayando que el modelo CI sigue siendo marco de referencia para investigaciones sobre comprensión y para el diseño de tecnologías educativas. Singer (2024) revisa cuatro contribuciones teóricas clave —representación proposicional, el modelo CI, modelos de situación multidimensionales y búsqueda en memoria global— y detalla cómo la distinción macroestructura/microestructura de van Dijk y Kintsch ha sido extendida y empíricamente validada a lo largo de cuatro décadas. Gernsbacher (2024) compara el modelo CI con el Structure Building Framework, destacando las fortalezas del CI en especificidad proposicional y mecanismos de integración.
3.2 Del texto a la educación: base textual, modelo situacional y aprendizaje
Wolfe y Bowdle (2024), en el mismo número especial, traducen la distinción entre estructura superficial, base textual y modelo situacional en recomendaciones prácticas para la instrucción universitaria. Argumentan que estrategias como releer y subrayar fortalecen primariamente la base textual, mientras que aquellas que activan conocimiento previo fortalecen el modelo situacional —el nivel más asociado con aprendizaje duradero. Van den Broek y Kendeou (2024) extienden esta distinción, argumentando que el aprendizaje requiere una comprensión profunda que va más allá de la construcción de un modelo situacional básico, incorporando procesos de revisión y reestructuración de conocimientos previos.
Butcher (2024) demuestra cómo el modelo CI puede servir como marco para diseñar y evaluar tecnologías educativas, tendiendo un puente explícito entre la teoría clásica de comprensión y los entornos digitales contemporáneos, incluidos los mediados por IA. Y Hattan y Kendeou (2024), en Educational Psychologist, abogan por expandir la ciencia de la lectura más allá de conceptualizaciones centradas en la fonología hacia un marco integrador que incorpore conocimiento previo, perspectivas culturalmente responsivas y procesos de comprensión, con el modelo CI como fundamento teórico explícito.
3.3 Evidencia meta-analítica: la estructura textual como ingrediente activo
La investigación sobre instrucción en estructura textual confirma que enseñar a reconocer la organización del texto mejora la comprensión, especialmente en textos expositivos académicos (Meyer, 2011; Williams, 2018). Peng et al. (2024), en un meta-análisis bayesiano de red con 52 estudios, identificaron que la combinación de identificación de idea principal + estructura textual + parafraseo constituye la fórmula de intervención más efectiva para lectores con dificultades, y que la instrucción en conocimiento de fondo es requisito para que las estrategias sean eficaces. Este hallazgo ofrece evidencia meta-analítica robusta de que el concepto de superestructura de van Dijk y Kintsch no es solo una categoría teórica, sino un ingrediente activo verificable en la comprensión.
En otras palabras, el lector competente no “lee linealmente”: navega jerarquías, detecta el esqueleto conceptual y monitorea consistencia. Este repertorio es el mismo que se requiere para auditar un output de IA.
Anatomía del Texto y Modelos de Comprensión
Sección 3 — De la microestructura al modelo situacional
Los tres planos de la anatomía textual
Van Dijk & Kintsch (1983): el lector construye representaciones en tres niveles. Primero explóralos, luego clasifica fragmentos reales.
Microestructura
Cohesión entre oraciones: conectores, pronombres, relaciones proposicionales. El "pegamento" que enlaza una idea con la siguiente.
Macroestructura
Organización temática: ideas principales, jerarquía de temas, extracción del sentido global mediante reglas de reducción.
Superestructura
Patrón del tipo textual: argumentativo, expositivo, narrativo. Activa expectativas sobre tesis, evidencias o secuencias.
🪞 Reflexión metacognitiva
El modelo CI sigue vigente: Discourse Processes (2024)
18 comentarios en honor a Walter Kintsch (1932–2023). ¿Puedes predecir qué autores validan la teoría y cuáles la traducen a educación?
🔮 Antes de explorar: predice
Abajo hay 7 autores/equipos del número especial. Haz clic en cada uno para asignarlo al cluster que creas correcto. Luego verifica.
🔬 Validación Teórica
🎓 Traducción Educativa
McNamara et al. (2024)
Introducción editorial: trazan el impacto de Kintsch desde el modelo proposicional hasta LSA y conexiones con LLMs actuales. El CI sigue siendo marco de referencia para comprensión y tecnologías educativas.
Singer (2024)
Revisa 4 contribuciones: representación proposicional, CI, modelos situacionales multidimensionales y búsqueda en memoria global. La distinción macro/micro ha sido validada empíricamente por 4 décadas.
Gernsbacher (2024)
Compara CI con Structure Building Framework. Destaca fortalezas del CI en especificidad proposicional y mecanismos de integración.
Wolfe & Bowdle (2024)
Traducen la distinción superficie/base textual/modelo situacional en recomendaciones para instrucción universitaria. Releer fortalece la base; activar conocimiento previo fortalece el modelo situacional — el nivel del aprendizaje duradero.
Van den Broek & Kendeou (2024)
El aprendizaje requiere comprensión profunda que va más allá del modelo situacional básico: incorpora revisión y reestructuración de conocimientos previos.
Butcher (2024)
El CI como marco para diseñar y evaluar tecnologías educativas — puente explícito entre teoría clásica y entornos digitales, incluidos los mediados por IA.
Hattan & Kendeou (2024)
Abogan por expandir la ciencia de la lectura más allá de la fonología: integrar conocimiento previo, perspectivas culturalmente responsivas y procesos de comprensión, con el CI como fundamento.
⟡ Un modelo de 1983 que sigue operando en 2024
El CI no es solo historia: es infraestructura teórica activa para diseñar educación, evaluar tecnología y entender cómo la lectura se conecta con los LLMs contemporáneos.
Audita un output de IA con la anatomía textual
Un sistema generativo produjo este párrafo. Usa los tres niveles de análisis para detectar qué funciona y qué falla.
🔍 Auditoría en tres niveles
⟡ Fórmula meta-analítica: Peng et al. (2024)
52 estudios, meta-análisis bayesiano de red → La combinación más efectiva para lectores con dificultades:
Requisito previo: instrucción en conocimiento de fondo. La superestructura de van Dijk & Kintsch no es solo categoría teórica — es ingrediente activo verificable.
🔮 METACOGNICIÓN FINAL
4. Memoria semántica: la infraestructura cognitiva del significado
La comprensión no se limita al texto; requiere acceder a redes de conocimiento general. La memoria semántica se define como el sistema de conocimiento conceptual y factual que permite comprender significados y relaciones entre conceptos, relativamente independiente del contexto episódico (Tulving, 1972). En lectura, esta memoria funciona como un “motor de inferencias”: permite completar información implícita, desambiguar términos y evaluar plausibilidad. En términos del modelo CI, la memoria semántica aporta el conjunto de asociaciones que se activan durante la construcción y que luego se integran o inhiben según coherencia (Kintsch, 1988).
4.1 Del dicotomía al continuo: repensar la frontera episódico-semántica
Debates contemporáneos confirman que la frontera entre memoria episódica y semántica es más porosa de lo que la formulación original sugería. De Brigard et al. (2022), en el editorial del número especial que conmemora los 50 años de la distinción de Tulving, argumentan que los hallazgos emergentes cuestionan la separación tajante. Gentry y Buckner (2024) profundizan esta revisión proponiendo que las memorias se transforman gradualmente a lo largo de un continuo mediante un proceso de “semantización”: la información episódica pierde progresivamente su anclaje contextual y se integra en redes conceptuales más abstractas. Addis y Szpunar (2024) van más allá del simple continuo episódico-semántico y proponen un modelo multidimensional de representaciones mentales que caracteriza la memoria a lo largo de múltiples dimensiones interactuantes, reconceptualizando el conocimiento semántico como participante en un espacio representacional rico. A nivel neural, Tanguay et al. (2023), en un estudio de fMRI con 48 participantes, encontraron que los tipos de memoria comparten una red cerebral común pero difieren en magnitud de activación, con las semánticas personales ocupando una posición intermedia que respalda la perspectiva de continuo.
4.2 Terminología compartida y mecanismos del conocimiento previo
La naturaleza multidisciplinaria de la investigación semántica genera riesgos terminológicos. Reilly et al. (2024), en un esfuerzo de consenso con más de 50 autores, establecen un glosario semántico interdisciplinario con definiciones para 17 constructos fundamentales que cruzan la ciencia cognitiva, la lingüística y la IA. Este recurso es relevante porque el presente artículo transita exactamente entre esos campos: lo que “semántico” significa para un neurocientífico, un lingüista y un ingeniero de sistemas RAG no es idéntico, y la clarificación terminológica fortalece el puente conceptual.
En el plano educativo, la relación entre conocimiento previo y aprendizaje es menos lineal de lo que se asume. Simonsmeier et al. (2022), en un meta-análisis con 8.776 tamaños de efecto, revelan una “paradoja del conocimiento previo”: aunque las diferencias individuales en conocimiento previo son altamente estables, su poder predictivo sobre las ganancias de aprendizaje es cercano a cero, con variabilidad enorme. El efecto depende del tipo, calidad y organización del conocimiento, no solo de su cantidad. Schneider y Simonsmeier (2025) identifican 16 mecanismos cognitivos y motivacionales a través de los cuales el conocimiento previo afecta el aprendizaje, proponiendo el marco Triple-M (Múltiples Mediaciones Moderadas). Hattan et al. (2024), en una revisión sistemática de 54 estudios sobre activación de conocimiento previo, completan el puente entre los modelos de comprensión (sección 3) y la memoria semántica: las técnicas que hacen explícita la conexión entre lo que el lector sabe y lo que el texto presenta mejoran la construcción del modelo situacional.
Memoria Semántica: Infraestructura Cognitiva del Significado
Sección 4 — Del almacén pasivo a la infraestructura dinámica
¿Dónde termina lo episódico y empieza lo semántico?
Tulving (1972) propuso una dicotomía. 50 años después, la evidencia la disuelve. Primero, ubica cada tipo de memoria donde creas que pertenece.
EPISÓDICA
INTERMEDIA
SEMÁNTICA
El eje se disuelve: de dicotomía a espacio multidimensional
Lo que ubicaste como "intermedio" es exactamente donde la dicotomía falla. Las memorias no caen limpiamente en dos cajas — se transforman a lo largo de un continuo por semantización (Gentry & Buckner, 2024): la información episódica pierde anclaje contextual y se integra en redes abstractas. Addis & Szpunar (2024) van más allá: proponen un espacio representacional multidimensional donde "semántico" y "episódico" son solo dos de muchas dimensiones.
De Brigard et al. (2022) CUESTIONA
Editorial del número especial por los 50 años de Tulving: los hallazgos emergentes cuestionan la separación tajante episódica-semántica. Abre la puerta a la revisión del modelo clásico.
Gentry & Buckner (2024) PROPONE PROCESO
La "semantización": las memorias se transforman gradualmente — la información episódica pierde anclaje contextual y se integra en redes conceptuales abstractas. Es un proceso, no una categoría.
Addis & Szpunar (2024) AMPLÍA MODELO
Van más allá del continuo lineal: proponen un modelo multidimensional de representaciones mentales. El conocimiento semántico participa en un espacio representacional rico, no solo en un extremo del eje.
Tanguay et al. (2023) EVIDENCIA NEURAL
fMRI (n=48): los tipos de memoria comparten una red cerebral común pero difieren en magnitud de activación. Las semánticas personales ocupan posición intermedia — respaldo neural directo para el continuo.
¿Más conocimiento previo = más aprendizaje?
Antes de ver los datos, tu intuición: si un estudiante ya sabe mucho sobre un tema, ¿aprenderá más en una clase sobre ese tema?
La paradoja del conocimiento previo (Simonsmeier et al., 2022)
El efecto depende del tipo, calidad y organización del conocimiento, no solo de su cantidad. No importa cuánto sabes — importa cómo está organizado y cómo se conecta con la nueva información.
🧩 ¿Base textual o modelo situacional?
Wolfe & Bowdle (2024) distinguen: algunas estrategias fortalecen la base textual, otras el modelo situacional. Clasifica cada una.
⟡ Triple-M: Múltiples Mediaciones Moderadas
Schneider & Simonsmeier (2025) identifican 16 mecanismos cognitivos y motivacionales por los que el conocimiento previo afecta el aprendizaje. No es un canal directo: es una red de mediaciones donde la organización, la activación y la conexión con la tarea determinan el impacto — exactamente como funciona (o falla) la recuperación en un sistema RAG.
Memoria Semántica Humana ↔ Sistema RAG
La implicación del texto: la memoria semántica es una infraestructura dinámica — y sus principios se transfieren al diseño de recuperación en IA. ¿Qué se transfiere y qué no?
Memoria Semántica
Sistema RAG
🔍 ¿Se transfiere o no? Evalúa cada principio
📖 ¿Qué significa "semántico"? Depende de quién lo dice
Reilly et al. (2024), con 50+ autores, crearon un glosario de 17 constructos. Tres lecturas del mismo término:
⟡ Implicación clave
La memoria semántica no es un almacén pasivo que se "consulta" — es una infraestructura dinámica cuya efectividad depende de cómo se activa, organiza y conecta con la tarea. Esta lección es directamente transferible al diseño de sistemas RAG — y a la competencia del usuario que debe evaluar si un sistema recuperó bien.
5. Creación semiótica y conceptual: producir sentido, no solo recuperar información
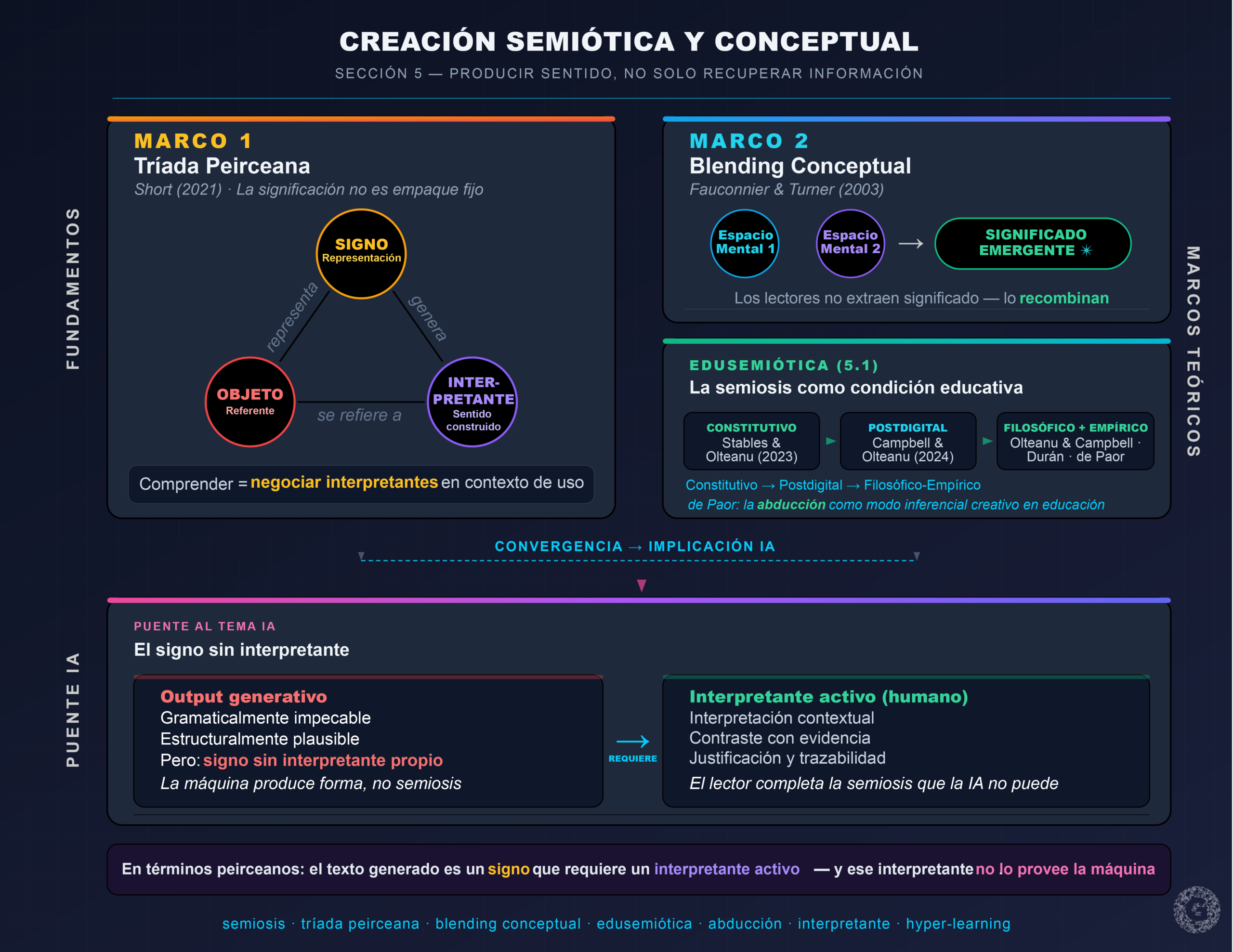
Si la memoria semántica es infraestructura, la semiosis es el proceso: producir significado mediante signos, objetos e interpretantes. En la tradición peirceana, la significación no es un “empaque” fijo; depende de interpretaciones encadenadas en contextos de uso (Short, 2021). Este enfoque resulta relevante para la lectura académica: comprender implica negociar interpretantes —qué cuenta como evidencia, qué inferencia es válida, qué concepto se construye.
A nivel cognitivo, la creación conceptual también se ha explicado como integración o blending: combinar estructuras de distintos espacios mentales para producir un significado emergente (Fauconnier & Turner, 2003). Este marco ilumina por qué los lectores pueden producir ideas nuevas al leer: no solo extraen, sino que recombinan.
5.1 Edusemiótica: la semiosis como proceso educativo
El movimiento de la edusemiótica ha consolidado la perspectiva de que toda educación implica procesos de signos. Stables y Olteanu (2023) argumentan que comprender el aprendizaje requiere comprender cómo los organismos producen significado a través de signos, posicionando la semiosis no como complemento teórico sino como condición constitutiva de la educación. Campbell y Olteanu (2024) extienden esta perspectiva al contexto postdigital, proponiendo un marco integrativo que combina la biosemiótica peirceana con la semiótica social para abordar la producción de sentido multimodal en entornos mediados por tecnología. Su propuesta resulta particularmente relevante para el argumento de este artículo: en contextos donde los textos son co-producidos por humanos e IA, la semiosis opera en capas adicionales de mediación que requieren interpretantes más sofisticados.
Olteanu y Campbell (2024) llevan el argumento al terreno filosófico de la educación, proponiendo un marco edusemiótico peirceano que incorpora la mediación tecnológica como dimensión constitutiva del aprendizaje. A nivel empírico, Durán Salas (2023) muestra cómo las tríadas de significado semiótico operan como mecanismo pedagógico concreto en el aprendizaje conceptual, y de Paor (2023) aplica la abducción peirceana —el modo inferencial creativo y generador de hipótesis— a conversaciones de mentoría docente, demostrando cómo la inferencia abductiva impulsa la producción de sentido y el aprendizaje profesional.
Memoria Semántica: Infraestructura Cognitiva del Significado
Sección 4 — Del almacén pasivo a la infraestructura dinámica
¿Dónde termina lo episódico y empieza lo semántico?
Tulving (1972) propuso una dicotomía. 50 años después, la evidencia la disuelve. Primero, ubica cada tipo de memoria donde creas que pertenece.
EPISÓDICA
INTERMEDIA
SEMÁNTICA
El eje se disuelve: de dicotomía a espacio multidimensional
Lo que ubicaste como "intermedio" es exactamente donde la dicotomía falla. Las memorias no caen limpiamente en dos cajas — se transforman a lo largo de un continuo por semantización (Gentry & Buckner, 2024): la información episódica pierde anclaje contextual y se integra en redes abstractas. Addis & Szpunar (2024) van más allá: proponen un espacio representacional multidimensional donde "semántico" y "episódico" son solo dos de muchas dimensiones.
De Brigard et al. (2022) CUESTIONA
Editorial del número especial por los 50 años de Tulving: los hallazgos emergentes cuestionan la separación tajante episódica-semántica. Abre la puerta a la revisión del modelo clásico.
Gentry & Buckner (2024) PROPONE PROCESO
La "semantización": las memorias se transforman gradualmente — la información episódica pierde anclaje contextual y se integra en redes conceptuales abstractas. Es un proceso, no una categoría.
Addis & Szpunar (2024) AMPLÍA MODELO
Van más allá del continuo lineal: proponen un modelo multidimensional de representaciones mentales. El conocimiento semántico participa en un espacio representacional rico, no solo en un extremo del eje.
Tanguay et al. (2023) EVIDENCIA NEURAL
fMRI (n=48): los tipos de memoria comparten una red cerebral común pero difieren en magnitud de activación. Las semánticas personales ocupan posición intermedia — respaldo neural directo para el continuo.
¿Más conocimiento previo = más aprendizaje?
Antes de ver los datos, tu intuición: si un estudiante ya sabe mucho sobre un tema, ¿aprenderá más en una clase sobre ese tema?
La paradoja del conocimiento previo (Simonsmeier et al., 2022)
El efecto depende del tipo, calidad y organización del conocimiento, no solo de su cantidad. No importa cuánto sabes — importa cómo está organizado y cómo se conecta con la nueva información.
🧩 ¿Base textual o modelo situacional?
Wolfe & Bowdle (2024) distinguen: algunas estrategias fortalecen la base textual, otras el modelo situacional. Clasifica cada una.
⟡ Triple-M: Múltiples Mediaciones Moderadas
Schneider & Simonsmeier (2025) identifican 16 mecanismos cognitivos y motivacionales por los que el conocimiento previo afecta el aprendizaje. No es un canal directo: es una red de mediaciones donde la organización, la activación y la conexión con la tarea determinan el impacto — exactamente como funciona (o falla) la recuperación en un sistema RAG.
Memoria Semántica Humana ↔ Sistema RAG
La implicación del texto: la memoria semántica es una infraestructura dinámica — y sus principios se transfieren al diseño de recuperación en IA. ¿Qué se transfiere y qué no?
Memoria Semántica
Sistema RAG
🔍 ¿Se transfiere o no? Evalúa cada principio
📖 ¿Qué significa "semántico"? Depende de quién lo dice
Reilly et al. (2024), con 50+ autores, crearon un glosario de 17 constructos. Tres lecturas del mismo término:
⟡ Implicación clave
La memoria semántica no es un almacén pasivo que se "consulta" — es una infraestructura dinámica cuya efectividad depende de cómo se activa, organiza y conecta con la tarea. Esta lección es directamente transferible al diseño de sistemas RAG — y a la competencia del usuario que debe evaluar si un sistema recuperó bien.
6. Búsqueda semántica y RAG: memorias externas para la inteligencia artificial (y para el lector)
6.1 El principio: recuperar por significado
En IA, la búsqueda semántica apunta a recuperar información por significado e intención, más allá del matching literal de palabras (Google Cloud, 2025). Esto se implementa con representaciones vectoriales (embeddings) que capturan relaciones semánticas en espacios de alta dimensión (IBM, 2024; Mikolov et al., 2013). Para texto a nivel de oración o párrafo, modelos como Sentence-BERT permiten embeddings comparables para similitud semántica, habilitando una recuperación más fina (Reimers & Gurevych, 2019).
6.2 RAG: memoria no paramétrica
Un paso adicional es la Generación Aumentada por Recuperación (RAG), que combina un modelo generativo con un componente de recuperación sobre una colección documental, funcionando como “memoria no paramétrica” que se consulta durante la respuesta (Lewis et al., 2020). Gao et al. (2024), en la encuesta más citada sobre RAG (con más de 1.800 citas), describen tres paradigmas —RAG Naive, RAG Avanzado y RAG Modular— y explican cómo esta arquitectura fusiona el conocimiento intrínseco de los modelos de lenguaje con repositorios externos dinámicos. Conceptualmente, RAG externaliza parte del conocimiento: en vez de “recordar” solo desde parámetros internos, el sistema recupera evidencia desde fuentes indexadas.
6.3 RAG como mente extendida: la conexión filosófica
La analogía más precisa entre RAG y la cognición humana la proponen Smart y Clowes (2025), quienes aplican la tesis de la mente extendida de Clark y Chalmers a los modelos de lenguaje. Su argumento es iluminador: la base de datos vectorial de un sistema RAG funciona de manera análoga al cuaderno de notas de Otto —el ejemplo clásico del externalismo cognitivo— donde los bucles de recuperación acceden a información externa para informar las respuestas del sistema. Esta perspectiva transforma la discusión: RAG no es simplemente una técnica de ingeniería, sino una formalización computacional de cómo la cognición puede distribuirse entre agentes internos y recursos externos. La conexión con la memoria semántica (sección 4) se torna explícita: así como la memoria del lector aporta el fondo de asociaciones que alimenta la comprensión, la base documental de un sistema RAG aporta el fondo de evidencias que alimenta la generación.
6.4 RAG en educación: del laboratorio al aula
La aplicación educativa de RAG ha experimentado un crecimiento explosivo. Li et al. (2025), en la revisión sistemática más comprehensiva hasta la fecha (51 estudios), documentan la integración de RAG en escenarios educativos que incluyen sistemas de aprendizaje interactivo, generación de contenido y evaluación, identificando desafíos clave como la mitigación de alucinaciones y la completitud del conocimiento recuperado. Swacha y Gracel (2025), en una encuesta paralela de 47 estudios sobre chatbots RAG educativos, encuentran que 37 de los 47 artículos fueron publicados en 2024, lo que revela la velocidad de adopción. Su conclusión es que la arquitectura relativamente simple de RAG la hace accesible para educadores sin formación técnica avanzada.
Varios estudios ofrecen evidencia de implementaciones concretas. Thüs et al. (2024) presentan OwlMentor, un sistema RAG diseñado para ayudar a estudiantes universitarios a comprender literatura científica mediante chats basados en documentos, generación automática de preguntas y cuestionarios. Thway et al. (2024) aportan una de las pocas evaluaciones que miden directamente resultados de aprendizaje (no solo satisfacción del usuario) al interactuar con un sistema RAG. Lang y Gürpinar (2025) evalúan un chatbot RAG en un curso asincrónico en línea y encuentran que los estudiantes con mayor conocimiento previo mostraron mayor propensión al uso, lo que conecta directamente con la paradoja del conocimiento previo discutida en la sección 4. Pampel et al. (2025) demuestran cómo educadores (no solo especialistas técnicos) pueden crear chatbots RAG específicos para sus cursos usando plataformas sin código, asegurando que las respuestas estén ancladas en conocimiento curado por el docente.
La conexión con el problema humano de la lectura académica es directa: la validez depende de si el lector y/o el sistema recupera fuentes pertinentes, integra coherentemente, explicita límites y conflictos, y evita alucinaciones o inferencias no sustentadas. RAG formaliza computacionalmente operaciones que el lector experto realiza cognitivamente, y sus limitaciones (alucinaciones, sesgos de recuperación, fragmentación del conocimiento) son análogas a las del lector que no activa adecuadamente su conocimiento previo o no detecta la superestructura del texto.
Búsqueda Semántica y RAG
Sección 6 — Memorias externas para la IA (y para el lector)
Búsqueda por significado, no por palabras
La búsqueda semántica recupera información por lo que significa, no por las palabras que contiene. Los textos se convierten en vectores (embeddings) que capturan relaciones de significado. Experimenta la diferencia.
🔍 Keyword vs. Semántica: compara resultados
Ante la misma consulta, dos sistemas buscan de manera radicalmente distinta.
🔤 Búsqueda por palabras clave
🧠 Búsqueda semántica
Observa: el resultado más relevante semánticamente no comparte ninguna palabra clave con la consulta — pero captura el mismo significado.
🧩 Predice la cercanía semántica
Los embeddings representan significado como posición en un espacio. Frases con significado similar quedan "cerca" aunque usen palabras distintas. ¿Puedes predecir?
B: "El can corre detrás del felino en el patio"
B: "Me senté en el banco del parque"
B: "La comprensión lectora del texto fue deficiente"
⟡ Lo que acabas de hacer es lo que hace un embedding
Cuando predijiste cercanía semántica, usaste tu memoria semántica (§4) para evaluar significado más allá de las palabras. Un embedding computacional intenta capturar exactamente eso: la posición de una frase en un espacio donde la distancia refleja diferencia de significado, no diferencia de palabras.
RAG: Recuperar → Integrar → Generar
RAG combina un buscador semántico con un generador. Tu trabajo: auditar si la generación es fiel a lo recuperado — o si "alucina".
El pipeline RAG en 3 pasos
Como el modelo Construcción-Integración de Kintsch (§3), pero computacional:
🔬 Simula una auditoría RAG
🔍 Audita el output: ¿fiel o alucinación?
⟡ RAG externaliza operaciones del lector experto
Lo que acabas de hacer — contrastar output con fuentes, detectar inflación, inversión semántica y generalización falsa — es exactamente lo que un lector experto hace cognitivamente cuando lee un texto académico. RAG formaliza computacionalmente esas operaciones, y sus fallas son análogas a las del lector que no activa conocimiento previo o no detecta la superestructura.
RAG como mente extendida
Smart & Clowes (2025) aplican la tesis de Clark & Chalmers: la cognición puede distribuirse entre agentes internos y recursos externos. ¿Qué comparten Otto, el lector y RAG?
La analogía de los tres "lectores"
Otto tiene Alzheimer y usa un cuaderno para recordar. Un lector consulta su memoria semántica. Un sistema RAG consulta su base vectorial. ¿Qué principio comparten?
OTTO (cuaderno)
Almacena información en un recurso externo. La consulta cuando necesita actuar. El cuaderno funciona como su memoria.
LECTOR EXPERTO
Activa redes de conocimiento previo (memoria semántica). Las consulta para inferir, desambiguar y evaluar plausibilidad.
SISTEMA RAG
Consulta una base documental vectorial. Recupera fragmentos relevantes y los integra para generar respuesta.
🧩 ¿Qué principio se comparte? ¿Cuál no?
📊 RAG en educación: la explosión 2024
⟡ La cognición distribuida requiere un lector distribuido
Si RAG es una "mente extendida" computacional, el lector que interactúa con ella necesita competencias textuales expandidas: no solo comprender textos, sino auditar cadenas de recuperación-generación, detectar alucinaciones, evaluar si la evidencia recuperada sustenta la respuesta. Eso es hyper-learning en acción: leer no solo textos, sino sistemas que producen textos.
7. Del uso estratégico del texto al hyper-learning
7.1 El marco: aprender, desaprender, reaprender y colaborar
Edward D. Hess (2020) plantea que el ritmo del cambio exige convertirse en hyper-learner: alguien capaz de aprender, desaprender y reaprender continuamente, superando sesgos cognitivos y defensas emocionales que bloquean la actualización de modelos mentales. A diferencia de marcos de alfabetización que especifican qué aprender sobre una tecnología, el hyper-learning es un meta-proceso que describe cómo aprender adaptativamente ante cualquier cambio —incluida la irrupción de la IA generativa. El ciclo de aprender-desaprender-reaprender (LUR, por sus siglas en inglés) no es exclusivo de Hess (tiene raíces en la formulación de Toffler), pero su contribución específica radica en vincular este ciclo con la colaboración, la humildad intelectual y la gestión emocional como condiciones necesarias para la adaptación continua.
Esta propuesta es especialmente pertinente cuando la IA genera contenido con apariencia de coherencia: el hyper-learning requiere habilidades para auditar texto, no solo consumirlo. Maheswara y Rifai (2023) aplican el ciclo LUR al aprendizaje personalizado de lenguas mediado por tecnología, demostrando que el marco funciona como estrategia pedagógica operativa. Menya-Olendo y Mawang (2024) ofrecen un tratamiento pedagógico detallado del ciclo, alineándolo explícitamente con la teoría constructivista del aprendizaje.
7.2 Alfabetización en IA como contenido del hyper-learning
Si el hyper-learning describe el proceso adaptativo, la alfabetización en IA (AI literacy) especifica un dominio de contenido que ese proceso debe abordar hoy. Laupichler et al. (2022), en una revisión de alcance de 30 estudios, concluyen que la alfabetización en IA en educación superior requiere refinamiento conceptual para aprendices no expertos. Ng et al. (2024) proponen el marco ABCE (Afectivo, Conductual, Cognitivo, Ético), cuyas dimensiones afectivas y éticas resuenan con el énfasis de Hess en la inteligencia emocional y la humildad intelectual como condiciones del hyper-learning. Allen y Kendeou (2024) proponen ED-AI Lit, un marco que fundamenta la alfabetización en IA en las ciencias conductuales y del cerebro, enfatizando el pensamiento crítico y las consideraciones éticas como componentes nucleares —una formulación que conecta la infraestructura cognitiva discutida en las secciones 2-4 con la práctica educativa.
7.3 Cuando la alfabetización en IA se encuentra con la lectura
La conexión más reveladora emerge cuando la alfabetización en IA se entiende no como un dominio separado de la lectura, sino como una nueva dimensión de la alfabetización misma. Aleman y Martinez (2024), en Reading Research Quarterly —la revista insignia de la International Literacy Association—, examinan cómo jóvenes interactúan críticamente con la IA desde tradiciones de alfabetización crítica, demostrando que la alfabetización en IA constituye una extensión natural de las competencias lectoras, no un campo independiente. Weber-Wulff et al. (2023), al probar herramientas de detección de texto generado por IA y encontrar limitaciones significativas de precisión, ofrecen un argumento empírico directo: dado que las herramientas automatizadas no pueden detectar fiablemente el texto generado por IA, los lectores-aprendices deben desarrollar ellos mismos la capacidad evaluativa para juzgar la calidad textual —encarnando precisamente el ciclo continuo de aprender, desaprender y reaprender.
7.4 Tres operaciones recurrentes para el uso estratégico del texto
En este contexto, el uso estratégico del texto implica tres operaciones que integran las competencias discutidas a lo largo del artículo:
Entender (comprender): identificar superestructura, tesis, supuestos y relaciones lógicas —es decir, realizar el análisis de la anatomía textual descrito en la sección 3, apoyado en la automatización neurocognitiva de la sección 2.
Interpretar (evaluar): contrastar con evidencia, detectar vacíos, revisar consistencia semántica —movilizando la memoria semántica (sección 4) y la producción de interpretantes (sección 5) para construir juicios fundamentados.
Dirigir (reformular): convertir outputs en estructuras útiles (argumentos, tablas, protocolos), y generar prompts o consultas de recuperación que incrementen trazabilidad —operando sobre la lógica de la búsqueda semántica y RAG (sección 6) como extensión de la competencia textual.
Estas operaciones alinean competencias lectoras con prácticas de ingeniería de información: seleccionar, generalizar, construir macroestructura y validar fuentes (van Dijk & Kintsch, 1983; Meyer, 2011).
Del Texto al Hyper-Learning
Sección 7 — Entender · Interpretar · Dirigir
Operación 1: Entender (comprender)
Identificar superestructura, tesis, supuestos y relaciones lógicas. Usa la automatización neurocognitiva §2 y la anatomía textual §3
🔍 Analiza la anatomía textual de este output
⟡ Entender = desmontar la anatomía
Acabas de aplicar las tres capas de van Dijk & Kintsch (micro, macro, super) a un output real. La automatización neurocognitiva (§2) te permitió leer fluidamente; la anatomía textual (§3) te dio las herramientas para detectar que la fluidez era ilusoria. Primera operación del hyper-learning completada.
Operación 2: Interpretar (evaluar)
Contrastar con evidencia, detectar vacíos, revisar consistencia semántica. Moviliza la memoria semántica §4 y la producción de interpretantes §5
🔺 Construye interpretantes — evalúa con la tríada
⟡ Interpretar = construir interpretantes evaluativos
Aplicaste tu memoria semántica para detectar que la genericidad bloquea la activación de conocimiento, y usaste la tríada para diagnosticar signos sin objeto. No es que el texto sea "malo" — es que no permite semiosis.
Operación 3: Dirigir (reformular)
Convertir outputs en estructuras útiles y generar consultas que incrementen trazabilidad. Opera sobre la lógica de búsqueda semántica y RAG §6
Ya lo entendiste (§2-3) y lo interpretaste (§4-5). Ahora: ¿cómo lo diriges hacia algo útil?
🎯 Reformula: del output genérico a la consulta estratégica
⟡ Dirigir = reformular para trazabilidad
No rechazaste el output — lo convertiste en punto de partida para consultas estratégicas, reestructuración macroestructural y verificación. Eso es usar la IA como herramienta, no como oráculo.
🔒 Completa las tres operaciones primero
Esta vista se desbloquea cuando hayas aplicado Entender, Interpretar y Dirigir.
Progreso: 0/3 operaciones
Las piezas son un sistema
Cada sección del artículo construyó una competencia. Las tres operaciones las integran. El hyper-learning es el marco que las sostiene.
ENTENDER
Identificar superestructura, tesis, supuestos. Analizar la anatomía textual para evaluar si hay estructura real o simulada.
INTERPRETAR
Contrastar con evidencia, detectar vacíos, construir interpretantes evaluativos. Activar conocimiento previo para juzgar plausibilidad.
DIRIGIR
Convertir outputs en estructuras útiles. Generar consultas que incrementen trazabilidad y calidad de recuperación.
El ciclo LUR: Aprender · Desaprender · Reaprender
Hess (2020): no basta con adquirir competencias — hay que revisar, soltar y reconstruir continuamente. Antes de cerrar, reflexiona sobre tu propio ciclo al leer este artículo.
APRENDER
Nueva información
DESAPRENDER
Revisar supuestos
REAPRENDER
Modelo actualizado
🟢 ¿Qué aprendiste que no sabías?
Quizás descubriste que la VWFA no es un "buzón de letras" sino un hub multimodal (§2). O que la correlación entre conocimiento previo y aprendizaje es ≈ 0 (§4). O que RAG es una formalización de lo que el lector experto ya hace (§6). Cada descubrimiento es una pieza nueva en tu modelo mental.
🟡 ¿Qué tuviste que desaprender?
Quizás creías que leer es "decodificar letras" — el modelo de surgimiento dice que es construir representaciones (§2). O que más conocimiento = más aprendizaje — la paradoja de Simonsmeier dice que no (§4). O que los outputs de IA son "textos" que se leen normalmente — la semiosis dice que son signos que requieren interpretante activo (§5). Desaprender no es olvidar: es revisar supuestos.
🟣 ¿Qué reaprendiste con nuevo sentido?
Quizás ya conocías a Kintsch pero ahora lo ves como marco para auditar IA (§3→§6). O ya usabas RAG pero ahora entiendes su analogía con la memoria semántica (§4→§6). Reaprender es lo que ya sabías pero reorganizado con nuevas conexiones. Eso es, literalmente, lo que la semantización describe: tu conocimiento episódico de estas secciones se está transformando en conocimiento semántico integrado.
Hyper-Learning = Lectura Experta del Siglo XXI
Las competencias textuales — entender estructura, interpretar con evidencia, dirigir hacia trazabilidad — son la bisagra entre la lectura humana y el uso estratégico de la IA. No son competencias nuevas: son las mismas que Kintsch describió en 1983, operando ahora sobre textos co-producidos por humanos y máquinas. La diferencia es que hoy, sin ellas, no hay aprendizaje — solo ilusión de comprensión.
8. Discusión: una alfabetización avanzada para IA basada en lectura, memoria y semiosis
Integrar IA en investigación y educación no es principalmente un problema de “herramientas”, sino de cognición aplicada. La paradoja de la lectura recuerda que el cerebro reutiliza —y, como muestran las evidencias recientes, genera— circuitos para una habilidad cultural; hoy, el desafío es análogo: reutilizar y extender competencias lectoras para una cultura de generación automatizada.
8.1 Alfabetización en prompts: competencia textual, no habilidad técnica
Un terreno donde esta convergencia se hace concreta es el diseño de prompts. Tour y Zadorozhnyy (2025) proponen una distinción conceptual fundamental entre “ingeniería de prompts” (prompt engineering, centrada en la tecnología y en optimizar el rendimiento de la IA) y “alfabetización en prompts” (prompt literacy, una competencia comunicativa y textual más amplia que integra lectura, escritura y análisis crítico). Esta distinción resuena con el argumento central de este artículo: la interacción efectiva con IA generativa no es primariamente un problema técnico, sino una extensión de las competencias textuales que la ciencia de la lectura y la semiótica han estudiado durante décadas.
Knoth et al. (2024) demuestran empíricamente que habilidades superiores de diseño de prompts predicen mayor calidad en los outputs de los modelos de lenguaje, estableciendo esta práctica como una competencia medible y enseñable. Woo et al. (2025) muestran que la formación estructurada en diseño de prompts transforma la interacción de los estudiantes con la IA desde un uso intuitivo y asistemático hacia una práctica deliberada y estratégica. Walter (2024) argumenta que la alfabetización en IA, la ingeniería de prompts y el pensamiento crítico constituyen tres competencias interrelacionadas e inseparables de una práctica educativa competente. Y Qian (2025), en la revisión sistemática más amplia del campo, documenta cómo la “alfabetización en prompts” está siendo progresivamente reconocida como habilidad fundacional en la educación mediada por IA.
8.2 Colaboración humano-IA en la escritura académica
En el terreno de la escritura académica, Nguyen et al. (2024) examinan cómo diez estudiantes de doctorado interactúan con un asistente de escritura generativo a lo largo de 626 actividades registradas. Mediante minería de procesos, encontraron que los estudiantes que se involucraron en procesos iterativos y altamente interactivos lograron mejor desempeño en escritura que quienes usaron la IA como fuente pasiva. Johnson y Paulus (2024) documentan un flujo de trabajo reflexivo para usar ChatGPT como compañero de escritura en investigación cualitativa, describiendo cómo los ciclos de retroalimentación en tiempo real favorecieron mayor profundidad y matiz, al tiempo que examinan críticamente el potencial de la IA para modelar las ideas de formas que podrían socavar la construcción de conocimiento. Perkins et al. (2024) ofrecen un marco práctico con la escala AIAS (Artificial Intelligence Assessment Scale), un sistema de cinco niveles para la integración ética de IA generativa en la evaluación educativa, adoptado en más de una docena de países.
8.3 Síntesis: la clave no es si la IA “escribe bien”
Desde la perspectiva integrada de este artículo, la clave no es si la IA “escribe bien”, sino si el lector-investigador:
- reconoce la anatomía textual del output (competencia estructural, sección 3),
- activa memoria semántica pertinente (conocimiento previo organizado y flexible, sección 4),
- construye interpretantes explícitos (semiosis activa, sección 5),
- usa búsqueda semántica/RAG para anclar afirmaciones en evidencia (memoria externa, sección 6),
- y mantiene la disposición de aprender, desaprender y reaprender que el hyper-learning exige (sección 7).
La alfabetización avanzada para IA no es, entonces, un dominio separado: es la convergencia de competencias lectoras, semánticas, semióticas y metacognitivas operando sobre un nuevo tipo de texto.
Tesis central
La alfabetización avanzada para IA no es un dominio separado: es la convergencia de competencias lectoras, semánticas, semióticas y metacognitivas operando sobre un nuevo tipo de texto. Explora cada competencia para ver su origen disciplinar y su aplicación concreta.
Distinción clave (Tour & Zadorozhnyy, 2025)
Haz clic en cualquier fila para ver por qué importa esta diferencia en la práctica educativa.
⚙️ Ingeniería de prompts
📖 Alfabetización en prompts
Actividad de comprensión
Lee el escenario e identifica qué competencia del modelo está siendo aplicada o ausente.
Escenario 1 de 4
9. Reflexiones
La lectura experta es un mecanismo de construcción de significado apoyado por estructuras textuales y memoria semántica; la neurociencia muestra que su eficiencia emerge de la plasticidad dependiente de la experiencia y la especialización funcional —la paradoja de la lectura—, y las evidencias recientes sugieren que esta reorganización ocurre por surgimiento de nuevas representaciones, no por competencia destructiva entre funciones preexistentes. En paralelo, las tecnologías de búsqueda semántica y RAG formalizan, en el plano computacional, operaciones análogas a la recuperación e integración de conocimiento, funcionando como “memorias externas” cuya lógica conecta con la tesis de la mente extendida.
En este cruce, el hyper-learning aparece como marco de acción: no basta con aprender; hay que reaprender críticamente en diálogo con textos humanos y generados, elevando la competencia textual a una habilidad estratégica. La alfabetización en IA y la emergente “alfabetización en prompts” no reemplazan esta competencia lectora: la presuponen y la extienden. El desafío para la educación y la investigación contemporánea es, entonces, formar lectores que no solo comprendan textos, sino que auditen, recombinen y verifiquen los productos de una cultura donde la generación automatizada es ubicua, lectores que, en términos peirceanos, sean capaces de producir interpretantes robustos ante signos de origen cada vez más diverso.
Tres movimientos de un argumento encadenado
El texto no presenta ideas paralelas: cada movimiento presupone y extiende al anterior. Explora cada nodo para ver su lógica interna y su conexión con los demás.
Conceptos clave del argumento
Cuatro nociones que el texto usa como bisagras. Cada una conecta una disciplina de origen con una exigencia concreta para la práctica educativa e investigativa.
El lector auditor en acción
Dado un escenario, identifica qué operación ejecutaría un lector que audita, recombina y verifica —en términos del argumento del texto.