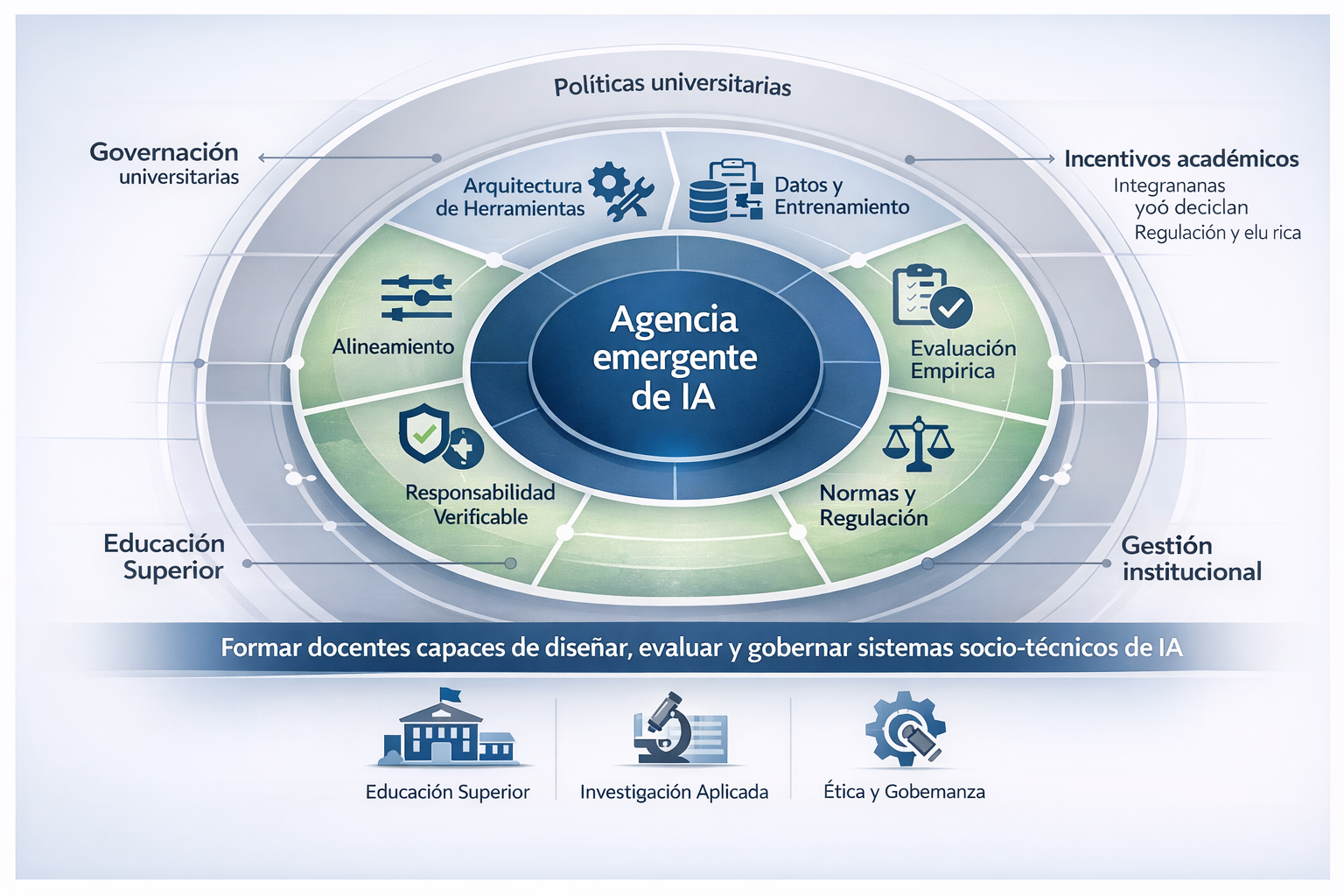
Introducción: Más allá del pánico tecnológico
Cuando el Center for AI Safety publicó su declaración sobre riesgos de extinción por inteligencia artificial (Center for AI Safety, 2023), equiparando la IA con pandemias y guerra nuclear, la conversación pública entró en un terreno familiar: el pánico tecnológico. No es la primera vez que una tecnología emergente genera narrativas apocalípticas, pero la velocidad con la que los modelos de lenguaje de gran escala (LLMs) han pasado del laboratorio a millones de usuarios plantea preguntas legítimas sobre agencia, control y consecuencias no intencionales.
Este artículo propone una lectura alternativa, anclada en un marco conceptual poco explorado en el debate público sobre IA: el trabajo de Robert Axelrod sobre la complejidad de la cooperación. La tesis central es que la “agencia” en IA contemporánea—desde ChatGPT hasta sistemas multiagente con acceso a herramientas—se entiende mejor como una propiedad socio-técnica emergente que surge de reglas locales, arquitectura de interacción, incentivos y gobernanza, más que de una “voluntad” intrínseca del sistema.
Esta perspectiva no niega riesgos, pero los reencuadra: del fatalismo sobre “superinteligencias rebeldes” hacia un programa científico-técnico basado en diseño institucional, evaluación empírica y gobernanza adaptativa.
El legado de Axelrod: De dilemas a ecologías cooperativas
El Dilema del Prisionero como organismo modelo
Robert Axelrod y William Hamilton revolucionaron nuestra comprensión de la cooperación con un trabajo seminal en Science que demostró cómo la cooperación puede emerger “entre egoístas” sin autoridad central (Axelrod & Hamilton, 1981). El mecanismo clave era la iteración: cuando los agentes interactúan repetidamente, estrategias cooperativas simples como “Tit-for-Tat” (reciprocidad directa) pueden dominar sobre estrategias puramente egoístas.
En La complejidad de la cooperación, Axelrod amplía este paradigma bipersonal hacia escenarios más realistas: múltiples actores, coaliciones, poder desigual, normas vulnerables y formación de estándares. El índice temático de la edición en español anticipa un catálogo de mecanismos relevantes: estrategias en dilema iterado, ruido, normas, bandos, estándares, nuevos actores y cultura.
Simulación como “tercera vía” científica
Un aporte metodológico crucial de Axelrod es posicionar la simulación basada en agentes (ABM) como método científico legítimo, distinto tanto de la inducción (patrones en datos) como de la deducción (pruebas a partir de axiomas). En su formulación, la simulación es especialmente útil cuando hay no linealidad y dependencia de trayectoria, permitiendo explorar consecuencias no evidentes de supuestos explícitos (Axelrod, 2003).
Las “propiedades emergentes”—efectos macroscópicos de agentes que interactúan localmente—son centrales en este enfoque. Un sistema puede exhibir comportamientos colectivos sorprendentes incluso con reglas simples. Este gesto metodológico es crucial para hablar de agentes de IA: los LLMs no encajan bien en la ficción de “racionalidad perfecta”, pero sí en la de sistemas adaptativos con restricciones, sesgos y fallos.
De autómatas a ecologías socio-técnicas: Una genealogía operativa
Para evitar el salto retórico “de pronto aparecen agentes todopoderosos”, es útil trazar una genealogía operativa que conecta conceptos y mecanismos:
- Autómatas y agentes simbólicos: Sistemas basados en reglas, planificación deliberativa y arquitecturas BDI (Beliefs-Desires-Intentions) que formalizan la agencia deliberativa bajo restricciones prácticas (Rao & Georgeff, 1995).
- ABM y simulación social: Modelado basado en agentes como instrumento para “generar” explicaciones macro desde mecanismos micro, destacando propiedades emergentes (Epstein, 1999).
- Agentes evolutivos: Algoritmos genéticos como teoría fundacional de adaptación en sistemas naturales y artificiales, demostrando que estrategias funcionales pueden emerger sin diseño central (Holland, 1992).
- LLMs y arquitectura Transformer: El salto hacia modelos de lenguaje de gran escala se apoya en la arquitectura “solo atención” propuesta por Vaswani et al. (2017), más paralelizable y eficiente que alternativas recurrentes, que se convirtió en base de la mayoría de LLMs contemporáneos.
- Agentes con herramientas: La “agencia” práctica se consolida cuando el modelo puede actuar sobre herramientas externas. Aproximaciones como ReAct (Yao et al., 2022) intercalan razonamiento y acción, mientras que Toolformer (Schick et al., 2023) demuestra aprendizaje auto-supervisado para decidir cuándo llamar APIs.
- Sistemas multiagente: Marcos como AutoGen (Wu et al., 2023) permiten orquestación de múltiples agentes conversacionales con roles específicos, herramientas y participación humana.
- Ecologías humano-IA gobernadas: El nivel final no es tecnológico sino institucional: normas, estándares, regulación y evaluación continua que configuran el ecosistema socio-técnico.
Autómatas y agentes simbólicos
Sistemas basados en reglas, planificación deliberativa y arquitecturas BDI.
ABM y simulación social
Explicación macro desde mecanismos micro; propiedades emergentes.
Agentes evolutivos
Estrategias funcionales emergen sin diseño central (algoritmos genéticos).
LLMs y arquitectura Transformer
“Solo atención” como base eficiente/paralelizable de la mayoría de LLMs.
Agentes con herramientas
La agencia práctica crece al actuar sobre herramientas externas.
Sistemas multiagente
Roles, herramientas y participación humana en marcos de coordinación.
Ecologías humano-IA gobernadas
Normas, estándares, regulación y evaluación continua del ecosistema.
Sistemas basados en reglas, planificación deliberativa y arquitecturas BDI (Beliefs-Desires-Intentions) que formalizan la agencia deliberativa bajo restricciones prácticas.
1) Decisión operativa
En 1 frase: ¿qué “mecanismo” explica este hito?
2) Evidencia del texto
Copia 6–14 palabras del texto que sustenten tu decisión.
3) Transferencia a LLM (tu traducción)
¿Cómo se ve este mecanismo en sistemas con LLM hoy?
4) Falla/fragilidad probable
¿Qué puede salir mal si se aplica mal?
5) Mitigación (micro-acción)
Define una acción concreta para reducir la fragilidad.
Paralelismos estructurales: Axelrod ↔ Agentes LLM
La tabla siguiente sintetiza cómo conceptos axelrodianos se traducen a desafíos contemporáneos de agentes de IA:
Axelrod → Traducción a Sistemas LLM Multiagente
Tabla de correspondencias para pasar de conceptos de ecologías cooperativas a diseño, evaluación y gobernanza de sistemas de agentes basados en LLM.
| Concepto en Axelrod | Traducción a agentes LLM | Implicación para desmitificar |
|---|---|---|
|
Estructura Expansión del paradigma bipersonal a múltiples bandos y poder desigual |
Sistemas multiagente con roles, negociación y coordinación entre modelos y herramientas | La dinámica relevante no es “una mente”, sino interacciones; el riesgo se analiza en términos de protocolos y gobernanza |
|
Incertidumbre “Habérselas con el ruido” como rasgo estructural |
Fallos de tool-use, ambigüedad de prompts, errores acumulativos en tareas largas | El riesgo inmediato suele ser fragilidad sistémica, no malevolencia; exige pruebas y mitigaciones |
|
Normas Promoción de normas y estabilidad normativa |
Alineamiento por preferencias (RLHF) y reglas explícitas (RLAIF / “Constitutional AI”) | La conducta es moldeable; el diseño de reglas y retroalimentación importa más que el fatalismo |
|
Estándares Establecimiento de estándares y formación de coaliciones |
Interfaces y estándares de herramientas/APIs; riesgos de cadena de suministro en aplicaciones LLM | La “agencia” depende de infraestructura y dependencias: se gobierna con estándares, auditoría y control de permisos |
|
Cultura “Diseminar cultura”: convergencia local y polarización global |
Convenciones emergentes y posibles sesgos colectivos en poblaciones de agentes en interacción | El foco pasa de “intención del agente” a “dinámica poblacional”: se requieren evaluaciones a escala sistema |
Tip: en móvil puedes desplazar la tabla horizontalmente (scroll) sin afectar el layout del sitio.
Alineamiento como institución, no como deseo
Uno de los avances más significativos en la práctica de agentes de IA es el desarrollo de técnicas de alineamiento que operacionalizan el problema de “hacer que los modelos hagan lo que queremos” como un problema de diseño institucional.
RLHF: Aprendizaje por preferencias humanas
El aprendizaje por refuerzo a partir de retroalimentación humana (RLHF) representa un cambio fundamental. En lugar de intentar especificar manualmente funciones de recompensa en entornos complejos, se aprenden estas funciones a partir de preferencias humanas entre trayectorias (Christiano et al., 2017). Ouyang et al. (2022) documentan el pipeline de InstructGPT, que combina demostraciones supervisadas, entrenamiento de un modelo de recompensa a partir de comparaciones humanas, y optimización por RLHF, reportando mejoras sustanciales en preferencia humana frente a modelos más grandes sin RLHF.
En tareas específicas como resumen, Stiennon et al. (2020) muestran que optimizar por preferencias humanas puede superar a optimizar métricas proxy como ROUGE según evaluaciones humanas, evidenciando que el alineamiento opera mejor con señales de valor humano que con proxies automatizados.
Constitutional AI: Normas explícitas
Anthropic propone un enfoque complementario con “Constitutional AI” (Bai et al., 2022), donde una lista de principios guía la auto-crítica del modelo y el aprendizaje por refuerzo desde feedback de IA (RLAIF), reduciendo dependencia de anotación humana costosa. Este diseño conecta directamente con el capítulo axelrodiano de “promoción de normas”: reglas explícitas + mecanismos de evaluación pueden desplazar el equilibrio conductual del sistema.
La lección institucional es clara: la conducta de estos sistemas no está “fija” en el entrenamiento base, sino que es moldeable mediante diseño de incentivos, retroalimentación y reglas. Esto reencuadra la “agencia” como un problema de gobernanza, no de esencia tecnológica inmutable.
Misión 1: Señal de valor (RLHF)
Objetivo: identificar qué intervención institucional reduce fragilidad y alinea conducta usando preferencias humanas.
Texto base (resumen operativo)
RLHF aprende funciones de recompensa desde preferencias humanas; Constitutional AI usa principios explícitos para auto-crítica y RLAIF. La conducta es moldeable por incentivos, reglas y evaluación continua: gobernanza, no esencia.
Bitácora de juego (decisiones → consecuencias)
Escenario
Un asistente LLM resume documentos. Los usuarios prefieren textos “seguros” pero reportan que a veces inventa datos. Debes rediseñar el sistema para mejorar preferencia humana SIN caer en métricas proxy.
Elige una intervención institucional
No es “qué quiere el modelo”, sino qué reglas, incentivos y evaluación configuran su conducta.
Justificación (metacognición)
Para ganar puntos extra debes: (1) nombrar el mecanismo, (2) citar una idea del texto, (3) proponer una prueba/mitigación.
Pista: si tu solución se basa solo en una métrica proxy, probablemente fallará.
Guardado local (en tu navegador). No afecta WordPress ni envía datos al servidor.
Evidencia contra la omnipotencia inmediata
Cuando se evalúan agentes en entornos realistas de largo horizonte, la imagen de agencia “todopoderosa” se debilita empíricamente:
WebArena: La brecha entre capacidad y desempeño robusto
Zhou et al. (2023) construyeron WebArena, un entorno web realista y reproducible para evaluar agentes autónomos en tareas que requieren navegación, comprensión contextual y ejecución de múltiples pasos. Los resultados son reveladores: incluso un agente basado en GPT-4 logra una tasa de éxito end-to-end del 14,41% frente a 78,24% humano en su configuración reportada.
Esta brecha sustantiva en tareas largas sugiere que la autonomía robusta a gran escala no es una propiedad garantizada del estado actual de la tecnología. No estamos ante sistemas omnipotentes, sino ante sistemas que exhiben capacidades impresionantes en contextos controlados pero fragilidad significativa en escenarios abiertos.
AgentBench: Obstáculos sistemáticos
Liu et al. (2023), con AgentBench, proponen un benchmark multi-entorno y atribuyen fallos típicos a razonamiento y decisión a largo plazo, además de seguimiento de instrucciones en escenarios multi-turn. Observan disparidades significativas entre modelos cerrados y abiertos, reforzando que el “agente” es función del modelo subyacente, el toolkit disponible y el diseño de interacción.
Este tipo de evidencia no elimina riesgos futuros, pero obliga a reemplazar el fatalismo por un programa de medición y mejora incremental, donde cada avance debe demostrarse empíricamente en condiciones realistas.
Mini-cuento
A veces la IA se ve súper inteligente… pero cuando la tarea es larga y tiene muchos pasos, puede equivocarse. Por eso, no pensamos “es mágica”, sino: “probemos y mejoremos poquito a poquito”.
Lo que muestran las pruebas
En juegos de tareas largas (como navegar una web), las personas suelen ganar mucho más que la IA. Eso significa que la IA puede ser útil, pero también frágil cuando el camino es largo.
Idea clave: medir → aprender → mejorar (en vez de asustarnos o creer que es invencible).
Pista: en tareas largas, revisa el camino paso a paso.
Tu reflexión (1 frase)
Completa: “Hoy aprendí que la IA…”
Guardado local (solo en tu navegador).
El robot hace 2 pasos
El robot debe hacer una tarea simple: abrir una puerta y traer una llave. ¿Qué crees que pasa?
El riesgo más realista: Fragilidad socio-técnica
En aplicaciones prácticas, los riesgos suelen manifestarse como vulnerabilidades operacionales y de seguridad. El proyecto OWASP Top 10 para LLM Applications identifica riesgos concretos: inyección de prompts, manejo inseguro de salidas de modelos, y “excessive agency” (agencia excesiva) en agentes conectados a herramientas (OWASP, s.f.).
Este último punto merece atención especial: cuando un agente tiene permisos amplios para ejecutar acciones—borrar archivos, enviar emails, realizar transacciones—sin controles adecuados, la vulnerabilidad no proviene de “intención rebelde” sino de arquitectura mal instrumentada. Un prompt malicioso puede convertirse en una instrucción ejecutable, precisamente porque el sistema está diseñado para “actuar” sin las salvaguardas institucionales que esperaríamos en sistemas críticos.
Esto encaja con el capítulo axelrodiano de “ruido”: incluso si el objetivo es cooperativo, los errores y manipulaciones pueden producir resultados dañinos. La fragilidad sistémica es el riesgo inmediato, no la malevolencia emergente.
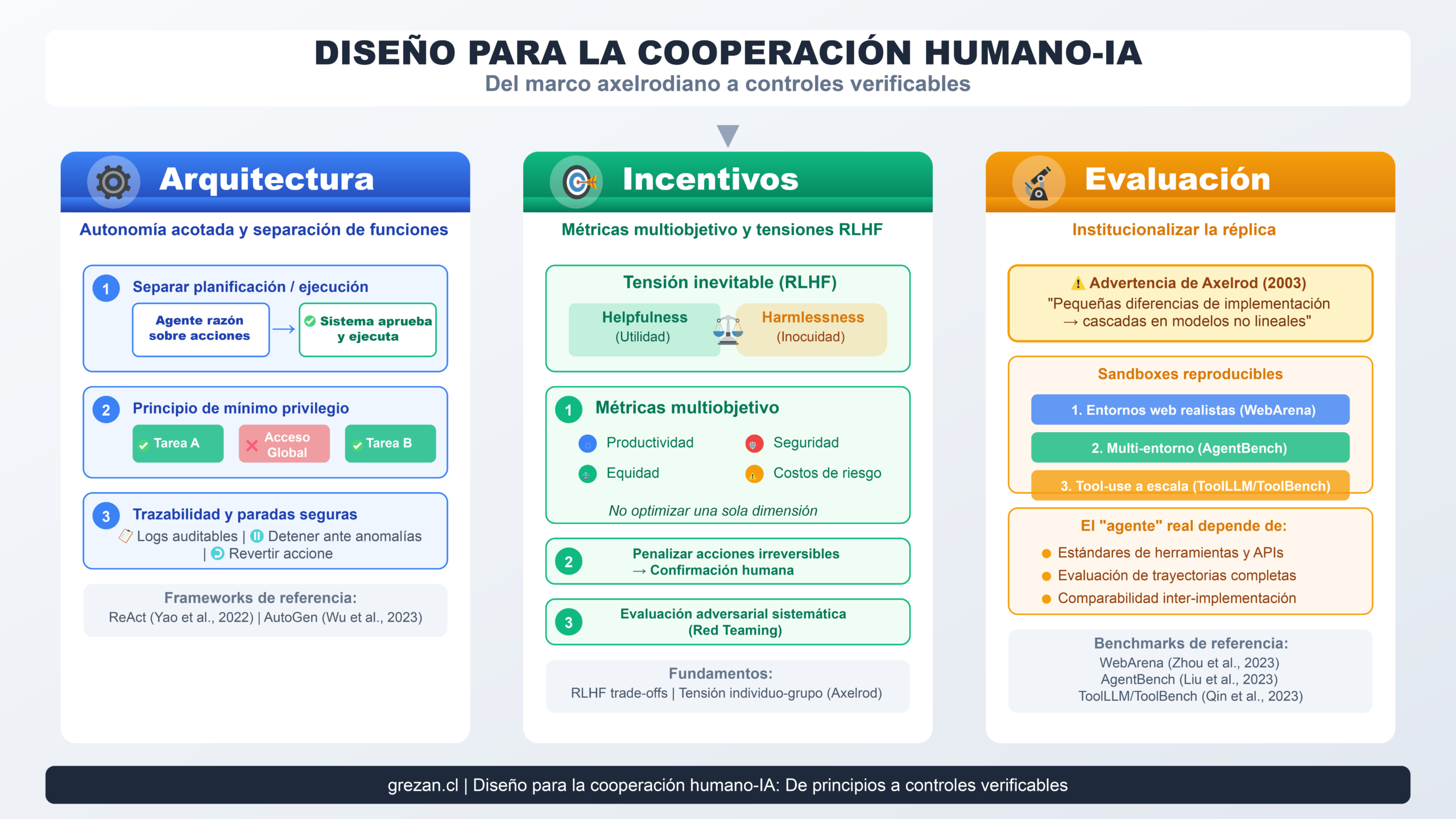
Diseño para la cooperación: De principios a controles verificables
Traducir el marco axelrodiano a propuestas concretas requiere operacionalizar “cooperación humano-IA” en arquitectura, incentivos y gobernanza:
Arquitectura: Autonomía acotada y separación de funciones
El diseño más robusto tiende a:
- Separar planificación de ejecución: El agente razona sobre acciones, pero la ejecución requiere confirmación o pasa por un sistema de permisos.
- Principio de mínimo privilegio: Permisos por tarea y por herramienta, no acceso global.
- Trazabilidad y paradas seguras: Logs auditables y capacidad de revertir o detener acciones automáticamente ante anomalías.
ReAct (Yao et al., 2022) demuestra el valor de intercalar razonamiento y acción para reducir alucinación y mejorar interpretabilidad de trayectorias. AutoGen (Wu et al., 2023) muestra composición multiagente programable donde roles y responsabilidades están explícitos.
Incentivos: Métricas multiobjetivo
La literatura de RLHF indica tensiones inevitables, como trade-offs entre “helpfulness” (utilidad) y “harmlessness” (inocuidad). Esto recuerda la tensión axelrodiana individuo/grupo y la necesidad de integrar múltiples objetivos normativos.
En términos operativos:
- Métricas multiobjetivo: No solo productividad, sino seguridad, equidad y costos de riesgo.
- Penalizaciones por acciones irreversibles: Exigir confirmación humana para operaciones críticas.
- Evaluación adversarial: Probar sistemáticamente intentos de manipulación (red teaming).
Evaluación: Institucionalizar la réplica
Axelrod (2003) enfatiza que pequeñas diferencias de implementación pueden producir cascadas en modelos no lineales, advirtiendo sobre la necesidad de réplica y comparabilidad. WebArena y AgentBench responden precisamente a esta necesidad: crear sandboxes reproducibles antes de despliegues amplios.
Para tool-use, ToolLLM/ToolBench (Qin et al., 2023) propone datasets y evaluadores para medir capacidad de usar miles de APIs, evidenciando que el “agente” real depende de estándares de herramientas y evaluación de trayectorias, no solo del modelo base.
Gobernanza: Marcos técnicos y jurídicos
El ecosistema de gobernanza para IA está madurando rápidamente, convergiendo marcos técnicos, estándares y regulación:
Marcos de gestión de riesgo
El AI Risk Management Framework (AI RMF 1.0) del National Institute of Standards and Technology propone cuatro funciones centrales: GOVERN (gobernanza), MAP (mapeo de contexto), MEASURE (medición) y MANAGE (gestión), con énfasis en enfoques socio-técnicos y evaluación periódica de efectividad (NIST, 2023).
Estándares internacionales
ISO/IEC 42001:2023 define requisitos para sistemas de gestión de IA (SGIA) con mejora continua, institucionalizando responsabilidad y procesos en organizaciones (ISO, 2023a). ISO/IEC 23894:2023 ofrece guía específica de gestión de riesgos para IA y su integración en actividades organizacionales (ISO, 2023b).
Regulación: El AI Act europeo
El Reglamento (UE) 2024/1689 (AI Act) establece como objetivo promover una IA “centrada en el ser humano y fiable”, definiendo un enfoque basado en riesgo con obligaciones diferenciadas según categorías de sistemas (Unión Europea, 2024). El calendario de aplicación escalonado permite adaptación gradual, pero representa el marco regulatorio más comprehensivo a nivel global hasta la fecha.
Ética como reflexión normativa integral
UNESCO (2021) define la ética de la IA como reflexión normativa que atraviesa todo el ciclo de vida de los sistemas, enfatizando responsabilidad compartida de múltiples actores: desarrolladores, organizaciones implementadoras, gobiernos y sociedad civil. Esta perspectiva aleja la ética del terreno abstracto y la ancla en prácticas concretas de diseño, evaluación y gobernanza.
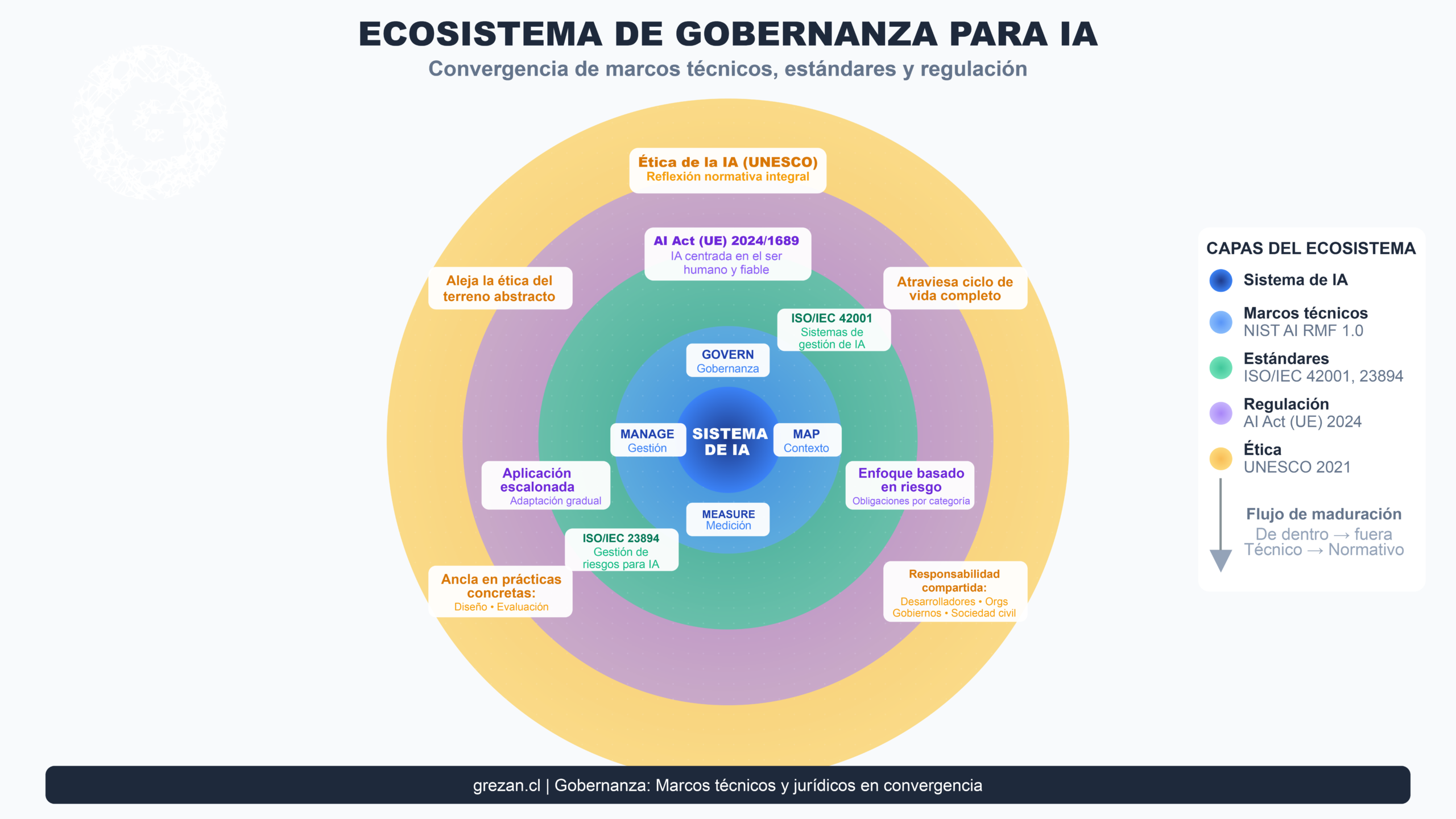
Tabla síntesis: Del principio al control verificable
Implicaciones para la educación y la investigación
Esta lectura axelrodiana de los agentes de IA tiene implicaciones directas para contextos educativos y de investigación:
Alfabetización crítica sobre IA
Formar a educadores y estudiantes no solo en “usar” herramientas de IA, sino en comprender sus arquitecturas de interacción, limitaciones empíricas y marcos de gobernanza. La narrativa apocalíptica paraliza; la comprensión de mecanismos empodera para diseño responsable y uso crítico.
Investigación situada en América Latina
Los marcos de gobernanza globales deben adaptarse a contextos locales. La investigación sobre agentes de IA en educación latinoamericana debe incluir evaluación de sesgos culturales en modelos predominantemente entrenados en inglés, acceso diferencial a tecnología, y diseño de políticas que reflejen prioridades educativas regionales.
Competencias para diseño socio-técnico
Los profesionales de la educación del futuro necesitan competencias que crucen fronteras disciplinarias: comprender lo suficiente de arquitecturas de IA para participar en conversaciones de diseño, suficiente de ética aplicada para identificar riesgos y valores en juego, y suficiente de evaluación empírica para distinguir capacidades reales de promesas infladas.
🎯 Diagnóstico de Competencias
Agentes de IA en Educación
Evalúa tu nivel en 3 competencias clave
Este diagnóstico te ayudará a identificar tus fortalezas y áreas de oportunidad en el trabajo con agentes de IA desde el marco axelrodiano.
Solo toma 3 minutos. Responde con honestidad.
Alfabetización crítica
Arquitecturas, limitaciones y gobernanza
Investigación situada
Contexto latinoamericano
Diseño socio-técnico
Ética aplicada y evaluación
¿Puedo explicar cómo funciona el alineamiento (RLHF) y por qué importa?
¿Conozco las limitaciones empíricas de agentes de IA en tareas realistas?
¿Puedo identificar y explicar marcos de gobernanza para IA?
¿Identifico sesgos culturales y lingüísticos en modelos entrenados en inglés?
¿Comprendo las brechas de acceso tecnológico en América Latina?
¿Diseño investigación que responde a prioridades educativas regionales?
¿Participo efectivamente en conversaciones de diseño técnico de sistemas con IA?
¿Identifico dilemas éticos y trade-offs en sistemas de IA educativos?
¿Distingo evidencia empírica sólida de promesas infladas sobre IA?
📊 Tu perfil de competencias
💡 Recomendación personalizada
Limitaciones del enfoque por analogía
La analogía Axelrod ↔ agentes LLM no es identidad. En ABM clásico, las reglas suelen ser explícitas y relativamente interpretables; en LLMs, el comportamiento proviene de modelos estadísticos de gran escala, con dependencias del contexto y de herramientas que pueden ser difíciles de aislar.
La brecha entre desempeño de laboratorio y robustez en tareas realistas muestra que la “capacidad agentiva” es sensible al entorno, al toolkit y a la evaluación. Cualquier generalización fuerte sin benchmark reproducible es, en el mejor de los casos, prematura.
Además, los sistemas de IA contemporáneos operan a escalas que desafían la intuición: millones de parámetros, conjuntos de datos masivos, interacciones globales simultáneas. La emergencia en ABM clásico suele involucrar decenas o cientos de agentes; la emergencia en ecosistemas de IA puede involucrar millones de usuarios interactuando con modelos entrenados en trillones de tokens. Esto introduce complejidades cualitativas nuevas que requieren métodos de análisis específicos.

Conclusión: Re-orientar desde el fatalismo hacia la agencia colectiva
El aporte principal de usar a Axelrod como eje conceptual no es tranquilizar ni negar riesgos, sino re-orientar el debate: de visiones apocalípticas centradas en intenciones metafísicas de “máquinas conscientes” hacia un programa científico-técnico basado en reglas de interacción, diseño de incentivos, evaluación empírica rigurosa y gobernanza adaptativa.
Los agentes de IA contemporáneos—desde LLMs instructivos hasta sistemas multiagente con acceso a herramientas—exhiben capacidades impresionantes en contextos específicos y fragilidad significativa en escenarios abiertos. Esta doble naturaleza exige respuestas institucionales: arquitecturas que acotan autonomía, incentivos que balancean múltiples objetivos, evaluaciones reproducibles que miden desempeño real, y marcos de gobernanza que asignan responsabilidades verificables.
La “agencia” artificial, lejos de ser una propiedad esencial e inmutable, emerge de la interacción entre modelo, arquitectura de herramientas, datos de entrenamiento, alineamiento, contexto de uso y marco regulatorio. Es, fundamentalmente, una propiedad socio-técnica que se diseña, se evalúa y se gobierna.
Una agenda razonable para 2026 incluye:
- Benchmarks reproducibles de largo horizonte y tool-use, con comparabilidad inter-implementación
- Análisis de dinámica poblacional de agentes: convenciones emergentes, polarización, cascadas en escenarios multiagente
- Integración de marcos de gestión de riesgo (NIST/ISO) con métricas técnicas y prácticas de seguridad (OWASP/MITRE)
- Estudios de cumplimiento y eficacia real del AI Act en sistemas agentivos, incluyendo sandboxes regulatorios y auditoría
Parafraseando a Axelrod: la cooperación entre egoístas requiere instituciones. La cooperación entre humanos y agentes de IA requiere, igualmente, instituciones—pero estas instituciones deben diseñarse, probarse y mejorarse iterativamente. El determinismo tecnológico es tan inútil como el pánico. Lo que necesitamos es agencia colectiva: diseño deliberado, evaluación rigurosa, gobernanza adaptativa.
En educación, esto significa formar profesionales que comprendan estos sistemas no como magia ni como amenaza existencial, sino como artefactos socio-técnicos cuyo comportamiento depende de decisiones de diseño, implementación y regulación. La pregunta no es “¿nos destruirán los agentes de IA?”, sino “¿qué instituciones, normas y prácticas necesitamos construir para que estos sistemas amplíen capacidades humanas de manera justa, segura y alineada con valores democráticos?”