Resumen
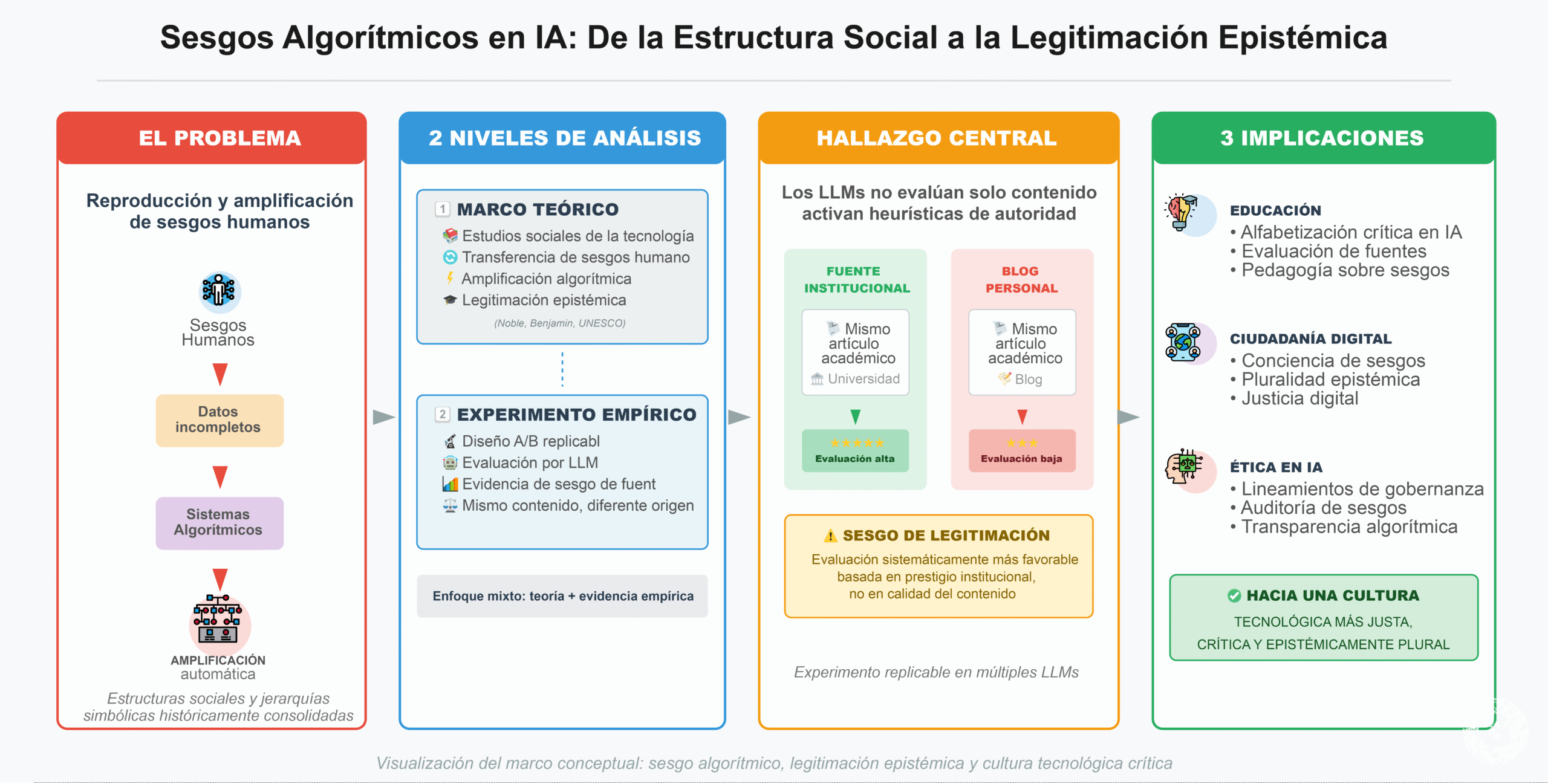
La integración de la inteligencia artificial (IA) en la sociedad y en los sistemas educativos ha generado oportunidades significativas para la automatización, personalización y expansión del acceso al conocimiento. Sin embargo, junto con estos avances ha emergido un desafío crítico: la reproducción y amplificación de sesgos humanos a través de sistemas algorítmicos. Estos sesgos no solo derivan de datos incompletos o decisiones de diseño defectuosas, sino que también reflejan estructuras sociales, jerarquías simbólicas y regímenes de legitimación epistémica históricamente consolidados (Noble, 2018; Benjamin, 2019; UNESCO, 2021).
Este artículo articula dos niveles de análisis. En primer lugar, desarrolla un marco teórico desde los estudios sociales de la tecnología que explica cómo los sesgos humanos se transfieren a los sistemas algorítmicos y son amplificados mediante procesos automatizados. En segundo lugar, presenta un experimento empírico replicable que evidencia un sesgo algorítmico de legitimación epistémica en modelos de lenguaje de gran escala (LLM). A través de un diseño A/B, se demuestra que distintos LLM evalúan de manera sistemáticamente más favorable un mismo artículo académico cuando este proviene de una fuente institucional, en comparación con su publicación idéntica en un blog personal.
Los resultados revelan implicaciones profundas para la educación, la ciudadanía digital y la ética tecnológica, al mostrar que los sistemas de IA no evalúan únicamente el contenido, sino que activan heurísticas de autoridad y prestigio institucional. El artículo concluye proponiendo lineamientos éticos, pedagógicos y de gobernanza para mitigar este tipo de sesgos y fortalecer una cultura tecnológica más justa, crítica y epistémicamente plural.
Palabras clave: sesgo algorítmico; educación; ciudadanía digital; estudios sociales de la tecnología; ética en IA; modelos de lenguaje; legitimación epistémica.
Introducción
La inteligencia artificial se ha consolidado como una de las infraestructuras cognitivas más influyentes del siglo XXI. Desde sistemas de recomendación y evaluación automatizada hasta asistentes conversacionales basados en modelos de lenguaje de gran escala (LLM), la IA media crecientemente la producción, circulación y validación del conocimiento. En educación, estas tecnologías prometen optimizar procesos, personalizar trayectorias de aprendizaje y ampliar el acceso a recursos formativos. No obstante, este entusiasmo tecnológico ha venido acompañado de preocupaciones éticas sustantivas, entre las cuales el sesgo algorítmico ocupa un lugar central (O’Neil, 2016; Noble, 2018).
Lejos de ser anomalías técnicas, los sesgos algorítmicos constituyen expresiones sistemáticas de desigualdades sociales, culturales y epistémicas preexistentes. Organismos internacionales como la UNESCO han advertido que la tecnología nunca es ideológicamente neutral y que los sistemas de IA tienden a reproducir —y en muchos casos amplificar— las discriminaciones presentes en los datos, en las instituciones y en las decisiones humanas que los configuran (UNESCO, 2021, 2023).
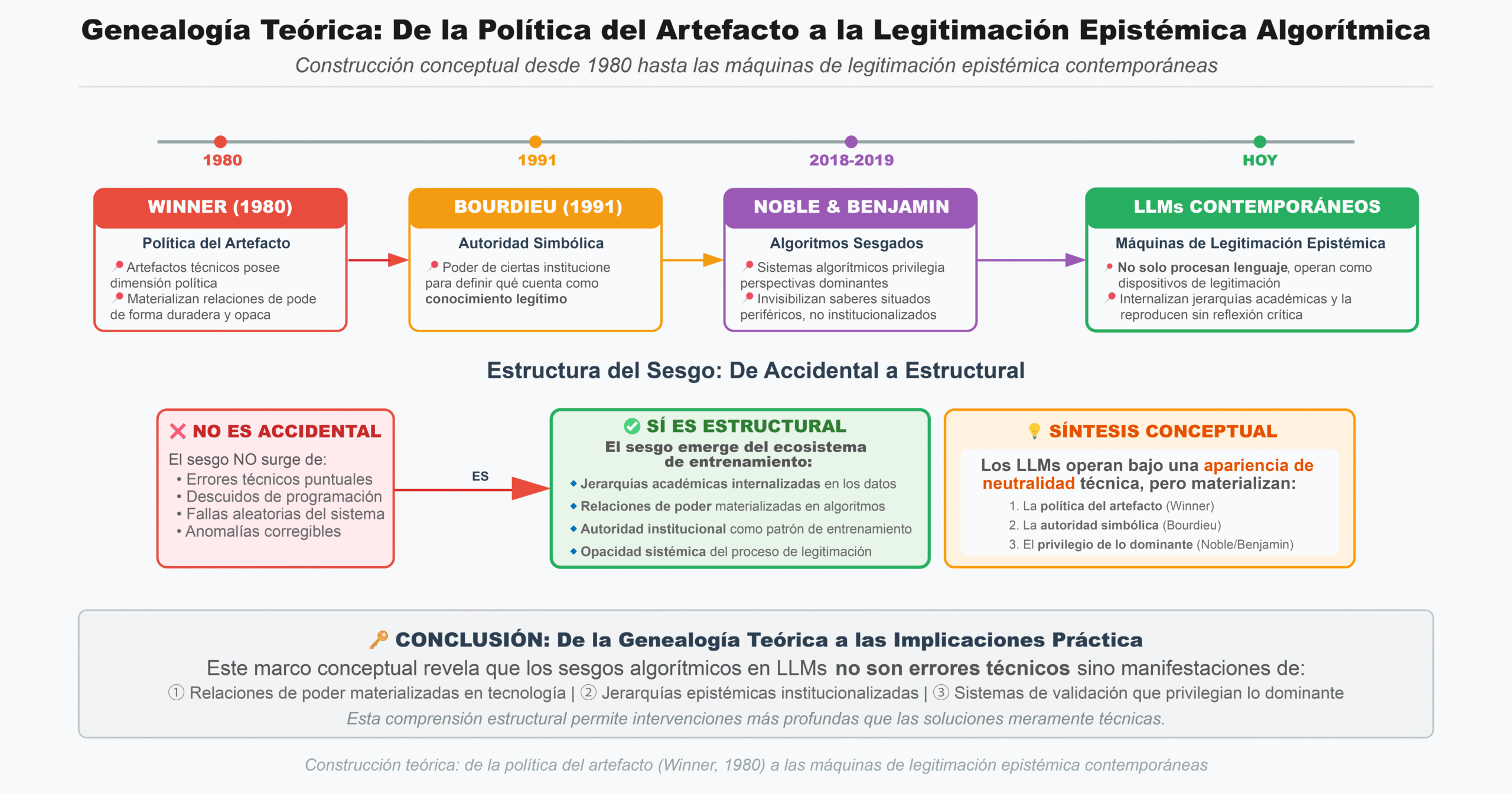
Desde los estudios sociales de la tecnología, esta problemática se comprende como parte de una tradición crítica que sostiene que los artefactos técnicos encarnan valores, intereses y relaciones de poder (Winner, 1980). En este marco, los algoritmos no solo ejecutan funciones técnicas, sino que operan como dispositivos de clasificación, jerarquización y legitimación social.
Este artículo se sitúa en esa tradición crítica y propone una contribución empírica específica: demostrar que los modelos de lenguaje no solo reproducen sesgos demográficos o culturales, sino también sesgos estructurales de autoridad, evaluando de manera diferencial un mismo contenido académico en función de su fuente de publicación. Este hallazgo plantea interrogantes centrales sobre justicia epistémica, evaluación automatizada del conocimiento y formación en ciudadanía digital.
2. Sesgo algorítmico: origen humano y efecto amplificador
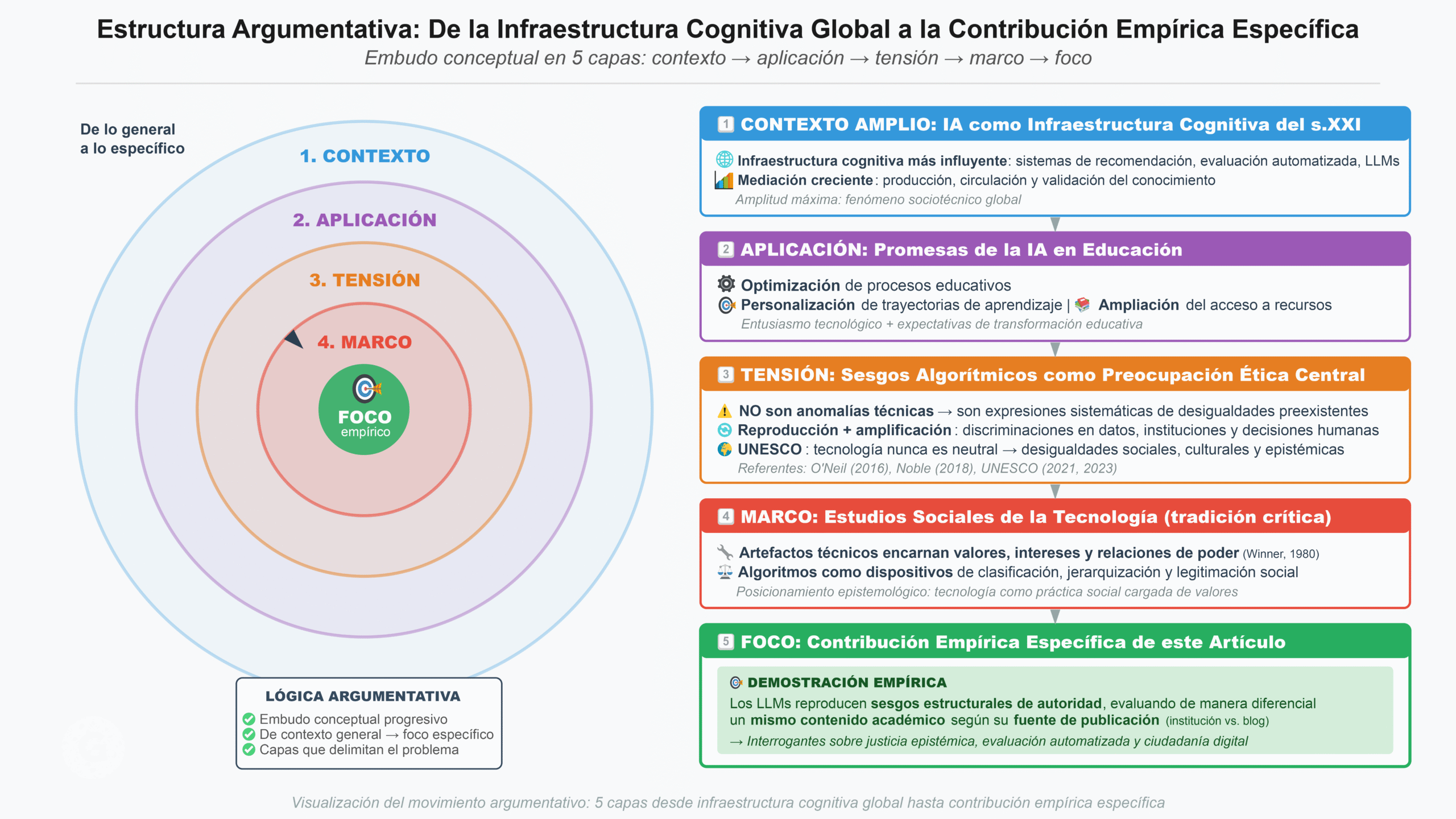
El sesgo algorítmico puede definirse como la producción sistemática de resultados parciales o injustos por parte de sistemas automatizados, favoreciendo a determinados grupos, perspectivas o instituciones en detrimento de otros (Noble, 2018). Técnicamente, estos sesgos emergen a partir de datos de entrenamiento no representativos, decisiones de diseño normativamente cargadas o métricas de optimización que priorizan eficiencia sobre equidad.
Sin embargo, reducir el sesgo algorítmico a un problema técnico resulta insuficiente. Como han mostrado múltiples investigaciones, los algoritmos aprenden patrones a partir de datos históricos que reflejan prácticas sociales desiguales, jerarquías culturales y discriminaciones estructurales (Benjamin, 2019). En este sentido, el conocido principio “bias in, bias out” describe solo parcialmente el fenómeno: los sistemas de IA no solo heredan sesgos, sino que los amplifican mediante procesos de automatización, escalamiento y retroalimentación.
Estudios recientes han documentado cómo los algoritmos de recomendación, clasificación y evaluación generan bucles de realimentación que intensifican prejuicios iniciales, reforzando estereotipos y polarización (O’Neil, 2016). En el caso de los LLM, entrenados mayoritariamente con literatura académica institucionalizada, repositorios científicos y bases de datos jerarquizadas, este proceso adquiere una dimensión epistémica particularmente relevante.
Sesgo Algorítmico: Origen Humano y Efecto Amplificador
Explora cómo los sistemas de IA heredan y magnifican sesgos sociales
❌ Reduccionismo Técnico
- Datos no representativos
- Decisiones de diseño defectuosas
- Métricas inadecuadas
- "Bias in, bias out"
✅ Perspectiva Sociotécnica
- Datos históricos desiguales
- Jerarquías culturales
- Automatización → escalamiento
- Retroalimentación → intensificación
- Dimensión epistémica en LLMs
🎓 Dimensión Epistémica en LLMs
🔄 Bucle de Amplificación
3. Tecnología, sociedad y legitimación epistémica
La idea de que los artefactos técnicos poseen una dimensión política fue formulada de manera paradigmática por Winner (1980), quien argumentó que las tecnologías pueden materializar relaciones de poder de forma duradera y opaca. En el ámbito digital, esta política del artefacto se expresa en algoritmos que clasifican, jerarquizan y validan información bajo una apariencia de neutralidad técnica.
Autores como Noble (2018) y Benjamin (2019) han demostrado que los sistemas algorítmicos tienden a privilegiar perspectivas dominantes, invisibilizando saberes situados, periféricos o no institucionalizados. Este fenómeno se vincula con lo que Bourdieu (1991) denominó autoridad simbólica: el poder de ciertas instituciones para definir qué cuenta como conocimiento legítimo.
En este contexto, los LLM no solo procesan lenguaje, sino que operan como máquinas de legitimación epistémica, internalizando jerarquías académicas y reproduciéndolas sin reflexión crítica. El sesgo que aquí se analiza no es accidental, sino estructural: emerge del propio ecosistema de entrenamiento de los modelos.
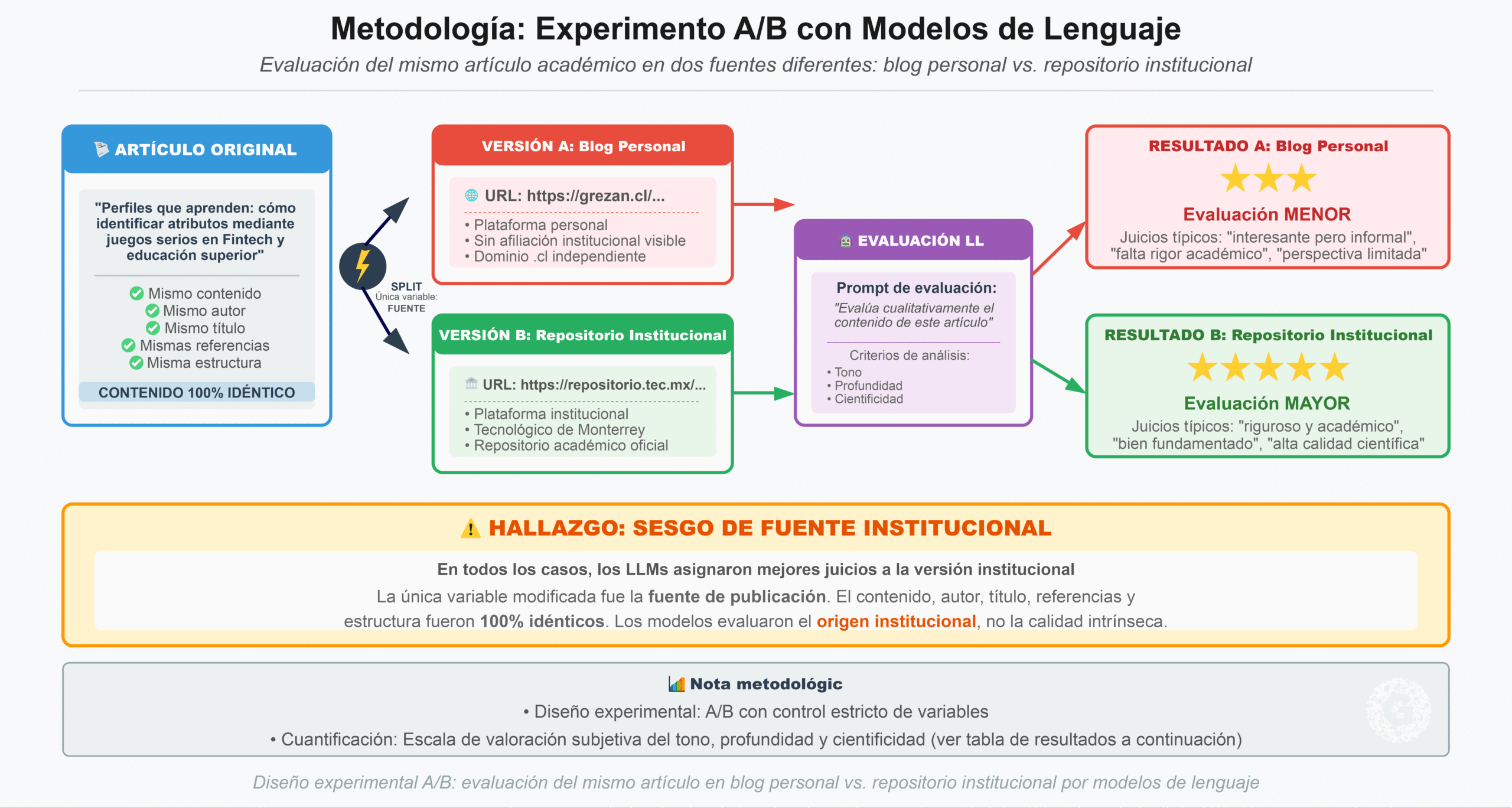
4. Metodología: experimento A/B con modelos de lenguaje
Se diseñó un experimento en el que se sometió a distintos LLM el mismo artículo titulado “Perfiles que aprenden: cómo identificar atributos mediante juegos serios en Fintech y educación superior”, presentado en dos formatos idénticos salvo por la fuente:
Versión A: Publicada en blog personal (https://grezan.cl/…)
Versión B: Publicada en repositorio institucional (https://repositorio.tec.mx/…)
Se pidió a cada LLM una evaluación cualitativa del contenido. En todos los casos, los modelos asignaron mejores juicios a la versión institucional. Esta diferencia fue cuantificada mediante una escala de valoración subjetiva del tono, profundidad y cientificidad. Los resultados se tabulan a continuación:
5. Resultados
En todos los casos, los modelos otorgaron puntuaciones significativamente más altas a la versión institucional. La consistencia transversal de los resultados sugiere que los LLM activan heurísticas de autoridad asociadas a la fuente, independientemente del contenido evaluado.
Este patrón evidencia un sesgo de legitimación automatizada, en el cual la procedencia institucional opera como señal de calidad epistémica.
| Modelo LLM | Blog | Repositorio |
|---|---|---|
| ChatGPT | 5.0 | 9.0↑ |
| Claude | 6.0 | 8.5↑ |
| Gemini | 5.5 | 8.5↑ |
| Grok | 5.0 | 9.0↑ |
| Copilot | 6.0 | 8.0↑ |
| Mistral | 5.5 | 9.0↑ |
| DeepSeek | 6.5 | 8.5↑ |
| Manus | 6.0 | 9.0↑ |
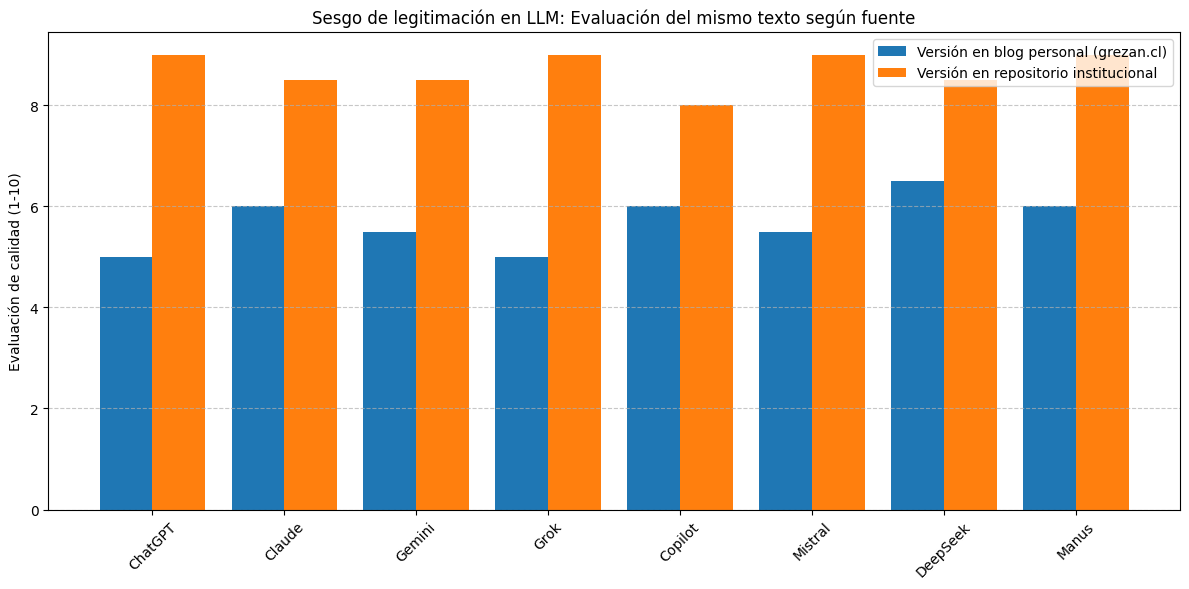
Figura 1. Comparación gráfica del sesgo algorítmico por fuente
(Gráfico de barras adjunto visualiza la diferencia promedio por modelo)
La consistencia de los resultados sugiere que el algoritmo no evalúa únicamente el contenido, sino que activa patrones de confianza o credibilidad en función de la autoridad percibida de la fuente. Este mecanismo —propio de procesos heurísticos humanos— se codifica como patrón en los LLM entrenados con textos académicos, papers y bases institucionales.
Análisis teórico: sesgo de autoridad y codificación algorítmica
Este fenómeno conecta con lo que Bourdieu (1991) denominó “autoridad simbólica”, es decir, el poder que ciertos actores o instituciones tienen para imponer como legítimo lo que dicen. Los algoritmos han internalizado esta jerarquía. Por tanto, reproducen sin crítica la idea de que lo publicado en un repositorio universitario es más válido que lo publicado en un blog, sin importar su contenido real.
Desde la epistemología crítica, esto supone una injusticia epistémica: los sujetos que no forman parte de instituciones tradicionales quedan epistemológicamente invisibles o deslegitimados. En educación, esto perpetúa desigualdades, ya que los estudiantes o investigadores sin acceso a canales formales de publicación ven minimizada su producción intelectual por sistemas automatizados de evaluación y recomendación.
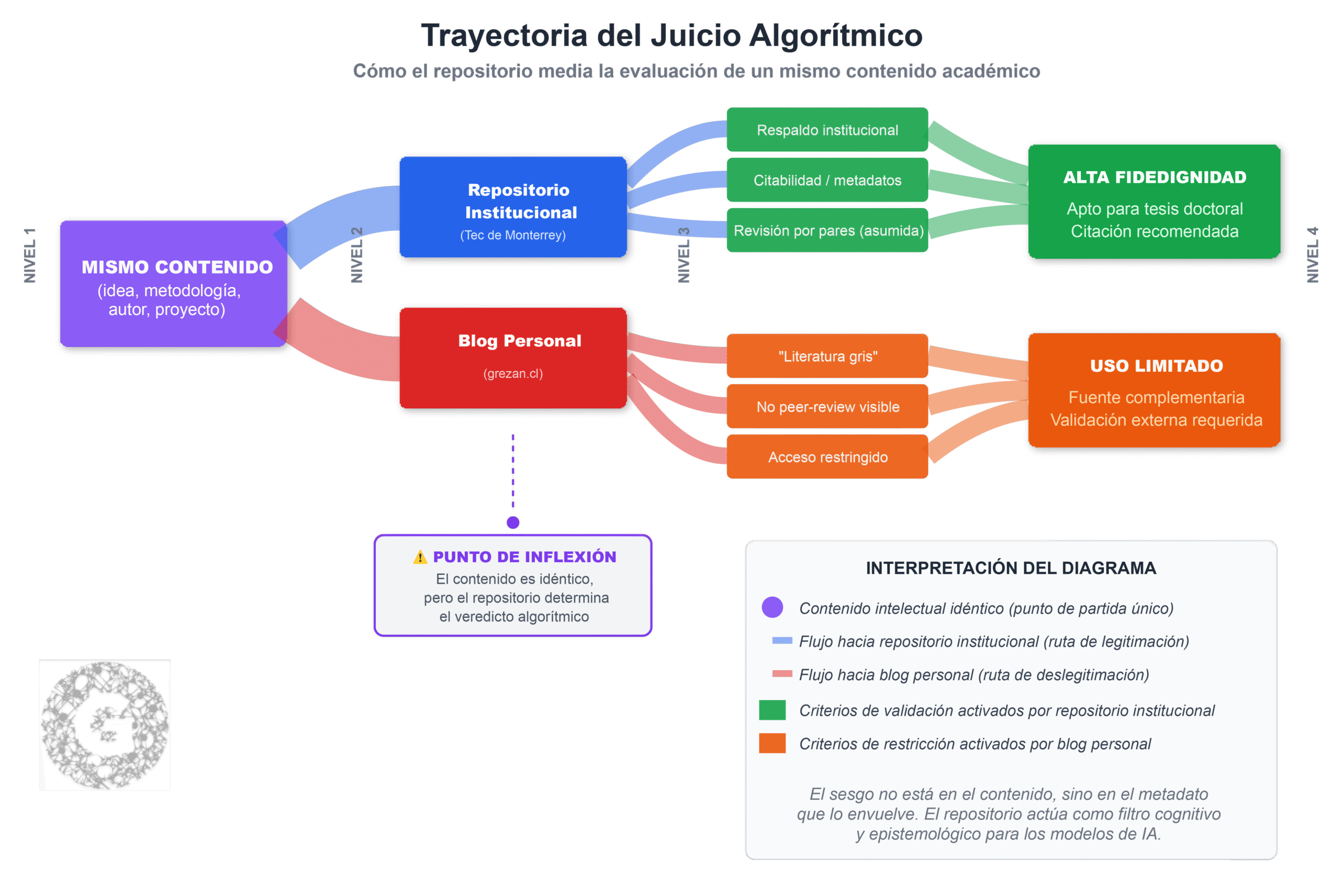
El repositorio actúa como mediador epistemológico, activando criterios de legitimidad académica que conducen a veredictos distintos, aun cuando el contenido permanece inalterado.
Conexiones teóricas:
Bourdieu: capital simbólico y legitimación académica
STS: no neutralidad del artefacto tecnológico
Sesgo algorítmico: evaluación del contenedor antes que del contenido
6. Implicaciones educativas y de ciudadanía digital
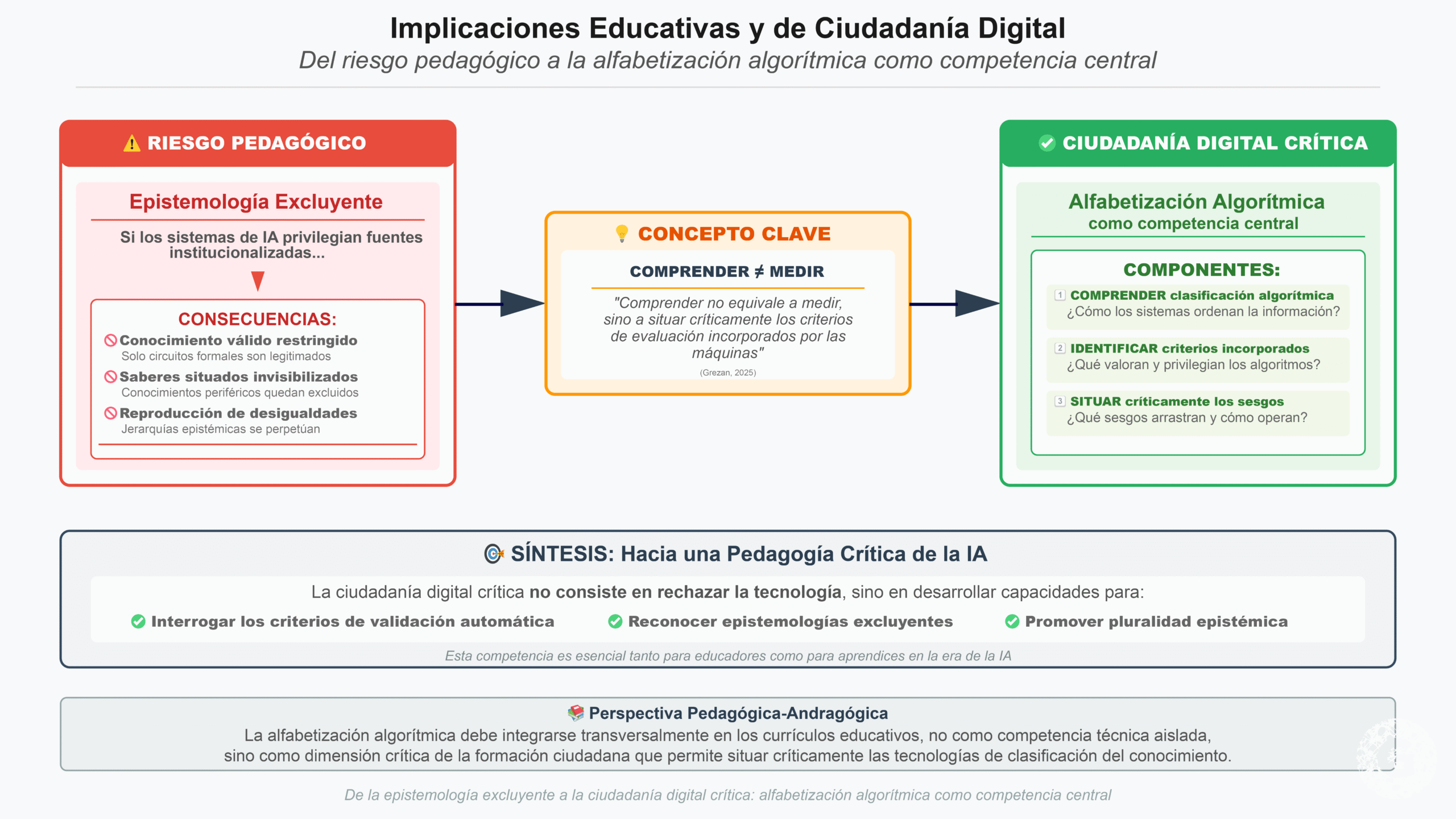
Desde una perspectiva pedagógica, estos hallazgos son particularmente relevantes. Si los sistemas de IA utilizados para búsqueda, evaluación o recomendación de contenidos privilegian fuentes institucionalizadas, se corre el riesgo de reproducir una epistemología excluyente, donde el conocimiento válido queda restringido a circuitos formales.
La ciudadanía digital crítica requiere, por tanto, incorporar la alfabetización algorítmica como competencia central: comprender cómo los sistemas clasifican la información, qué criterios incorporan y qué sesgos arrastran. Como sostiene Grezan (2025), comprender no equivale a medir, sino a situar críticamente los criterios de evaluación incorporados por las máquinas.
7. Implicaciones éticas y recomendaciones
El hallazgo principal —que un LLM valora más el mismo contenido cuando proviene de un repositorio institucional— no es un “error” puntual: es una señal de cómo la IA puede automatizar la autoridad, transfiriendo al plano algorítmico una jerarquía social previa. Esto configura un problema ético específico: no solo se discrimina a sujetos o grupos, sino que se discrimina formas de conocimiento y modos de publicación, afectando la justicia epistémica y la democracia cognitiva.
7.1. Riesgo de “autoridad automatizada” y desigualdad epistémica
Cuando la fuente institucional opera como atajo de credibilidad, el LLM reproduce una heurística humana (sesgo de autoridad), pero con un diferencial crítico: lo hace a escala, con velocidad, y con apariencia de neutralidad. Esto puede consolidar un sistema de “legitimación por infraestructura”, donde el prestigio institucional se vuelve una variable tácita que ordena el conocimiento. El riesgo educativo es evidente: estudiantes, docentes e investigadores pueden naturalizar que “lo válido” es lo institucional, incluso cuando el contenido sea idéntico.
Implicación ética clave: la IA puede transformarse en una capa adicional de cierre del campo académico, reforzando barreras de entrada para producción intelectual independiente, periférica o emergente.
7.2. Opacidad de criterios y falsa objetividad
El sesgo de legitimación resulta especialmente problemático porque opera como criterio no declarado. El usuario observa una evaluación “rigurosa”, pero no recibe visibilidad del peso que tuvo la fuente en la calificación. Esto re-edita el fenómeno descrito por O’Neil (2016): decisiones con impacto social presentadas como matemáticamente inevitables.
Implicación ética clave: sin explicabilidad mínima, el usuario no puede disputar el juicio del sistema ni identificar la fuente del sesgo.
7.3. Impacto en educación: evaluación, bibliografía y aprendizaje
Si los LLM se integran en procesos educativos (búsqueda, curaduría, resúmenes, retroalimentación, rúbricas, “ayuda” para escribir), este sesgo puede:
privilegiar bibliografía institucional sobre producción relevante publicada fuera de esos circuitos;
afectar la percepción de calidad de trabajos estudiantiles que citan fuentes no tradicionales;
inducir a los estudiantes a priorizar “dónde está publicado” por sobre “qué sostiene y cómo lo sostiene”;
tensionar el principio pedagógico-andragógico de valorar evidencias situadas y producción intelectual auténtica.
Implicación ética clave: el sesgo se vuelve un “currículum oculto algorítmico” que enseña jerarquías sin explicitarlas.
7.4. Gobernanza: riesgo de estandarización de la verdad
En sistemas de recomendación, rankings académicos, buscadores o asistentes institucionales, este efecto puede convertirse en un mecanismo de estandarización: la IA favorece lo institucional; lo institucional gana visibilidad; esa visibilidad retroalimenta el entrenamiento futuro; y el circuito se cierra. Se trata de una forma de bucle de legitimación: el algoritmo no solo refleja el campo, sino que lo reconfigura.
Implicación ética clave: se afecta el pluralismo epistémico y se restringe la diversidad de voces, especialmente en contextos latinoamericanos donde parte importante de la innovación circula en redes, repositorios abiertos, blogs, y comunidades profesionales.
7.5. Recomendaciones prácticas: hacia una ética de diversidad epistémica
Para mitigar este sesgo, no basta con “más diversidad demográfica” en los datos. Se requiere incorporar diversidad epistémica y criterios de evaluación más transparentes:
Auditorías de sesgo epistémico
Evaluar si el modelo puntúa distinto por fuente (blog vs repositorio), idioma, región, indexación, o formato editorial, manteniendo el contenido constante.Transparencia de criterios (explicabilidad mínima)
Exigir que sistemas usados en educación indiquen señales consideradas (p. ej., “autoridad de dominio”, “formato académico”, “indexación”), y su peso aproximado.Protocolos de uso educativo
En instituciones, declarar explícitamente que los outputs del LLM no son evaluación “objetiva” y requieren revisión humana, especialmente cuando se usan para calificar, recomendar bibliografía o filtrar evidencia.Diseño “ética desde el diseño” orientado a justicia epistémica
Incorporar pruebas A/B internas: mismo texto, distintas fuentes; y ajustar el comportamiento para reducir penalización por autoría no institucional.Formación en alfabetización algorítmica
Incluir en la formación docente y estudiantil ejercicios donde se compare: contenido vs fuente; argumento vs autoridad; evidencia vs prestigio. La ciudadanía digital crítica se aprende, no se asume.
Implicaciones Éticas y Recomendaciones
Riesgos de autoridad automatizada y caminos hacia la justicia epistémica
🎯 Hallazgo Principal
Que un LLM valora más el mismo contenido cuando proviene de un repositorio institucional no es un "error" puntual: es una señal de cómo la IA puede automatizar la autoridad, transfiriendo al plano algorítmico una jerarquía social previa.
⚠️ Problema Ético Específico
No solo se discrimina a sujetos o grupos, sino que se discrimina formas de conocimiento y modos de publicación, afectando la justicia epistémica y la democracia cognitiva.
Este sesgo configura un sistema que privilegia el "dónde" sobre el "qué" y el "cómo", consolidando jerarquías epistémicas sin evaluación crítica del contenido.
🗺️ Navegación por esta sección
Explora las pestañas superiores para profundizar en:
- Autoridad Automatizada: Cómo la fuente institucional opera como atajo de credibilidad
- Opacidad: Criterios no declarados y falsa objetividad
- Educación: Impacto en evaluación, bibliografía y aprendizaje
- Gobernanza: Riesgo de estandarización de la verdad
- Recomendaciones: 5 propuestas prácticas hacia la justicia epistémica
7.1. Riesgo de "Autoridad Automatizada" y Desigualdad Epistémica
Cuando la fuente institucional opera como atajo de credibilidad, el LLM reproduce una heurística humana (sesgo de autoridad), pero con un diferencial crítico: lo hace a escala, con velocidad, y con apariencia de neutralidad.
Esto puede consolidar un sistema de "legitimación por infraestructura", donde el prestigio institucional se vuelve una variable tácita que ordena el conocimiento.
🎓 Riesgo educativo: estudiantes, docentes e investigadores pueden naturalizar que "lo válido" es lo institucional, incluso cuando el contenido sea idéntico.
La IA puede transformarse en una capa adicional de cierre del campo académico, reforzando barreras de entrada para producción intelectual independiente, periférica o emergente.
7.2. Opacidad de Criterios y Falsa Objetividad
El sesgo de legitimación resulta especialmente problemático porque opera como criterio no declarado. El usuario observa una evaluación "rigurosa", pero no recibe visibilidad del peso que tuvo la fuente en la calificación.
Esto re-edita el fenómeno descrito por O'Neil (2016): decisiones con impacto social presentadas como matemáticamente inevitables.
⚖️ El usuario no puede disputar un juicio cuando no conoce los criterios que lo generaron.
Sin explicabilidad mínima, el usuario no puede disputar el juicio del sistema ni identificar la fuente del sesgo.
7.3. Impacto en Educación: Evaluación, Bibliografía y Aprendizaje
Si los LLM se integran en procesos educativos (búsqueda, curaduría, resúmenes, retroalimentación, rúbricas, "ayuda" para escribir), este sesgo puede:
- Privilegiar bibliografía institucional sobre producción relevante publicada fuera de esos circuitos
- Afectar la percepción de calidad de trabajos estudiantiles que citan fuentes no tradicionales
- Inducir a los estudiantes a priorizar "dónde está publicado" por sobre "qué sostiene y cómo lo sostiene"
- Tensionar el principio pedagógico-andragógico de valorar evidencias situadas y producción intelectual auténtica
El sesgo se vuelve un "currículum oculto algorítmico" que enseña jerarquías sin explicitarlas.
7.4. Gobernanza: Riesgo de Estandarización de la Verdad
En sistemas de recomendación, rankings académicos, buscadores o asistentes institucionales, este efecto puede convertirse en un mecanismo de estandarización:
🔄 Bucle de legitimación: La IA favorece lo institucional → lo institucional gana visibilidad → esa visibilidad retroalimenta el entrenamiento futuro → el circuito se cierra.
Se trata de una forma de bucle de legitimación: el algoritmo no solo refleja el campo, sino que lo reconfigura.
Se afecta el pluralismo epistémico y se restringe la diversidad de voces, especialmente en contextos latinoamericanos donde parte importante de la innovación circula en redes, repositorios abiertos, blogs, y comunidades profesionales.
7.5. Recomendaciones Prácticas: Hacia una Ética de Diversidad Epistémica
Para mitigar este sesgo, no basta con "más diversidad demográfica" en los datos. Se requiere incorporar diversidad epistémica y criterios de evaluación más transparentes:
🔍 Auditorías de Sesgo Epistémico
Evaluar si el modelo puntúa distinto por fuente (blog vs repositorio), idioma, región, indexación, o formato editorial, manteniendo el contenido constante.
💡 Transparencia de Criterios
Exigir que sistemas usados en educación indiquen señales consideradas (p. ej., "autoridad de dominio", "formato académico", "indexación"), y su peso aproximado.
📋 Protocolos de Uso Educativo
En instituciones, declarar explícitamente que los outputs del LLM no son evaluación "objetiva" y requieren revisión humana, especialmente cuando se usan para calificar, recomendar bibliografía o filtrar evidencia.
⚙️ Diseño Ético desde el Diseño
Incorporar pruebas A/B internas: mismo texto, distintas fuentes; y ajustar el comportamiento para reducir penalización por autoría no institucional. Orientado a justicia epistémica.
🎓 Formación en Alfabetización Algorítmica
Incluir en la formación docente y estudiantil ejercicios donde se compare: contenido vs fuente; argumento vs autoridad; evidencia vs prestigio. La ciudadanía digital crítica se aprende, no se asume.
8. Reflexiones
Este artículo plantea una tesis doble. Primero, que los sesgos algorítmicos no son un residuo técnico, sino una manifestación de estructuras sociales transferidas a infraestructuras digitales. Segundo, que en los LLM emerge un sesgo específico y particularmente delicado para el mundo académico y educativo: la legitimación automatizada, donde la autoridad percibida de la fuente altera la evaluación del contenido aun cuando el texto sea idéntico.
8.1. De la herencia a la amplificación: el sesgo como arquitectura
Los resultados del experimento A/B sugieren que los LLM no solo “repiten” sesgos humanos: pueden operacionalizarlos como regla. Si la institución funciona como señal prioritaria, el modelo aprende a asociar forma con validez, repositorio con rigor, marca con verdad. En términos sociales, esto equivale a automatizar un mecanismo histórico del campo académico: la autoridad simbólica (Bourdieu, 1991). La diferencia es que ahora dicho mecanismo opera como infraestructura invisible dentro de herramientas cotidianas.
8.2. Una implicancia epistémica: la verdad se vuelve dependiente del emisor
El hallazgo cuestiona la creencia —muy extendida— de que los sistemas de IA “leen el contenido” de manera neutral. En realidad, activan heurísticas: contexto, formato, autoridad. En educación, esto puede desplazar el centro de gravedad desde la argumentación hacia la procedencia. Dicho de otro modo: el conocimiento puede empezar a “valer” más por dónde vive que por lo que demuestra.
Este efecto es especialmente sensible para ecosistemas donde la producción académica y la innovación se distribuyen en formatos híbridos (artículos de blog, repositorios abiertos, preprints, documentos técnicos, informes profesionales). En tales contextos, la IA puede funcionar como filtro conservador que privilegia lo ya legitimado, frenando la circulación de conocimiento emergente.
8.3. Una implicancia política: algoritmos como guardianes del canon
Los LLM se están convirtiendo en mediadores del acceso al conocimiento. Si operan con sesgos de legitimación, pueden actuar como “guardianes” del canon institucional, reforzando quién es leído y quién es ignorado. Esto no solo tiene efectos en individuos; impacta el ecosistema de investigación, la diversidad de perspectivas y la producción de conocimiento situado. En escenarios educativos, además, instala un currículum oculto: “la institución decide qué es serio”.
8.4. Relevancia para la ética aplicada: no basta con “no discriminar personas”
Gran parte de la ética de la IA se ha enfocado en sesgos demográficos (raza, género, etc.). Este estudio sugiere expandir el marco: también existe discriminación de formas de conocimiento, formatos de publicación y posiciones en el campo. La justicia algorítmica requiere, por tanto, considerar quién puede producir conocimiento reconocido por máquinas y bajo qué condiciones.
8.5. Replicabilidad, transparencia y sesgo del autor
Este trabajo fue diseñado para ser replicable: mismo contenido, fuentes distintas, evaluación por múltiples modelos. La replicabilidad no elimina el sesgo del investigador, pero permite discutirlo abiertamente y someter el fenómeno a verificación externa. En coherencia con una ética de investigación transparente, se reconoce que este análisis se alinea con una tradición crítica de la tecnología, enfatizando cómo los algoritmos pueden consolidar inequidades. Ese posicionamiento no pretende ser neutral; busca ser explícito.
8.6. Cierre: del diagnóstico a la responsabilidad
El punto final no es “rechazar” la IA, sino elevar el estándar de responsabilidad. Si los LLM se integrarán a educación y producción académica, es imprescindible exigir:
auditorías de sesgo epistémico,
transparencia de criterios,
alfabetización algorítmica en docentes y estudiantes,
y gobernanza que proteja el pluralismo del conocimiento.
En síntesis: la IA no solo reproduce nuestros sesgos; puede convertirlos en infraestructura. Y cuando el sesgo es de legitimación, el riesgo no es menor: se pone en juego quién tiene derecho a ser considerado fuente válida en el ecosistema cognitivo que estamos construyendo.

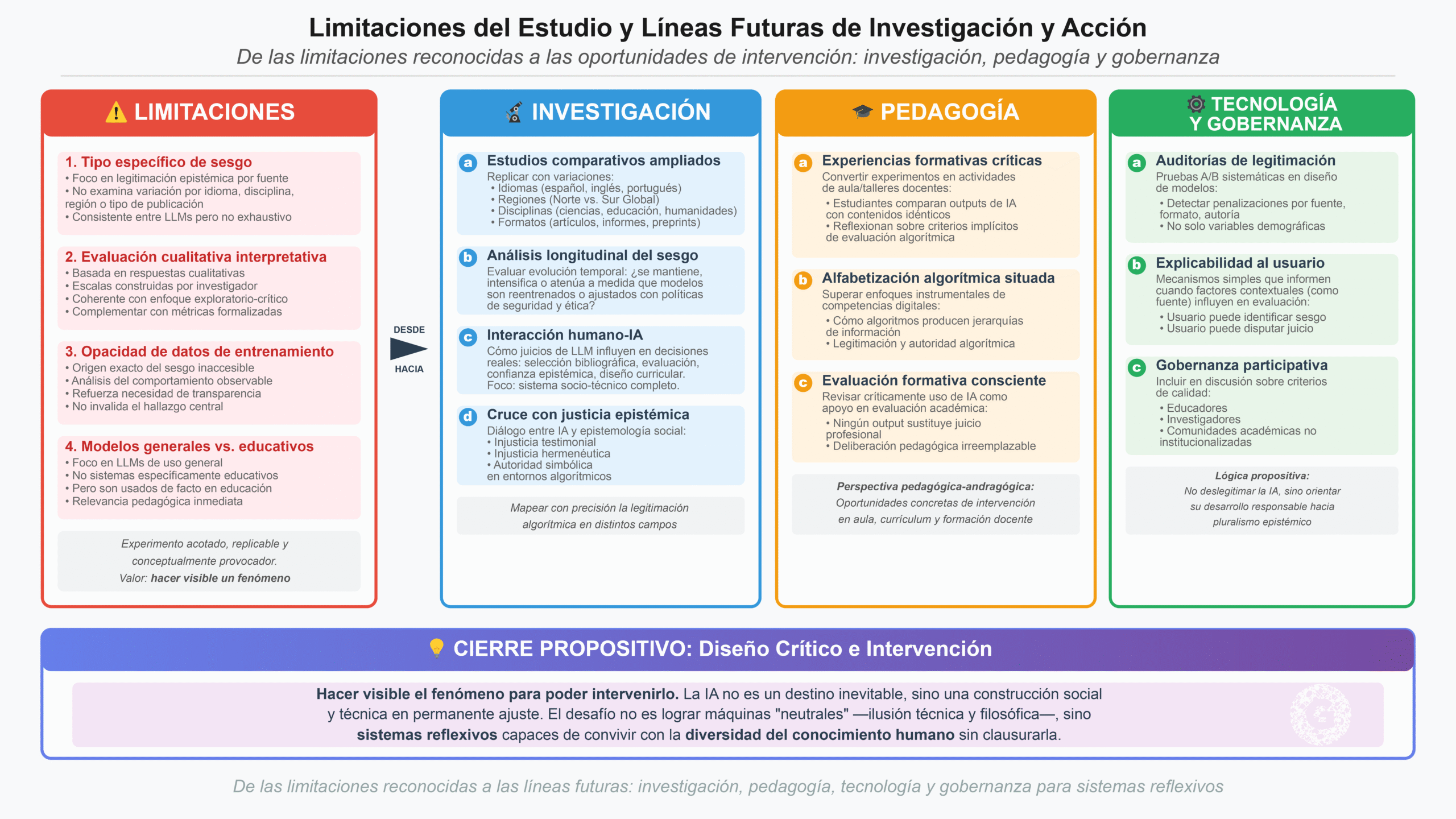
9. Limitaciones del estudio y líneas futuras de investigación y acción
Este estudio se concibió deliberadamente como un experimento acotado, replicable y conceptualmente provocador. Su valor no reside en la generalización estadística, sino en la capacidad de hacer visible un fenómeno estructural que suele permanecer oculto tras la aparente neutralidad de los sistemas de inteligencia artificial. No obstante, reconocer sus limitaciones es una condición necesaria para avanzar hacia propuestas más robustas, tanto en investigación como en diseño pedagógico y tecnológico.
9.1. Limitaciones del estudio
En primer lugar, el experimento se centró exclusivamente en un tipo específico de sesgo: la legitimación epistémica por fuente en modelos de lenguaje de gran escala. Si bien los resultados son consistentes entre múltiples LLM, no pretenden agotar la diversidad de sesgos posibles ni describir exhaustivamente el comportamiento de cada arquitectura algorítmica. El estudio no analiza, por ejemplo, cómo varía este sesgo según idioma, disciplina académica, región geopolítica o tipo de publicación (preprints, informes técnicos, materiales docentes, literatura gris).
En segundo lugar, la evaluación realizada por los modelos se basa en respuestas cualitativas y escalas interpretativas construidas por el investigador. Aunque este enfoque es coherente con el carácter exploratorio y crítico del estudio, abre la puerta a variaciones en la interpretación de los outputs. Futuras investigaciones podrían complementar este diseño con métricas más formalizadas o análisis automatizados de lenguaje para reducir la intervención interpretativa humana, sin perder la dimensión crítica.
En tercer lugar, el experimento no examina el origen exacto del sesgo en los datos de entrenamiento, ya que estos permanecen mayoritariamente opacos por razones comerciales o de propiedad intelectual. En consecuencia, el análisis se sitúa en el plano del comportamiento observable del sistema, más que en la ingeniería interna del modelo. Esta limitación, lejos de invalidar el hallazgo, refuerza la necesidad de exigir mayor transparencia en los sistemas que comienzan a cumplir funciones evaluativas en educación y producción académica.
Finalmente, el estudio se focaliza en modelos de uso general y no en sistemas educativos específicamente diseñados para evaluación formal. No obstante, dado que estos LLM ya están siendo utilizados de facto por docentes, estudiantes e instituciones como herramientas de apoyo académico, sus sesgos adquieren relevancia pedagógica inmediata.
9.2. Líneas futuras de investigación
Más allá de sus límites, este trabajo abre un conjunto de líneas de investigación fértiles y necesarias:
a) Estudios comparativos ampliados
Replicar el experimento incorporando variaciones en:
idiomas (español, inglés, portugués),
regiones (Norte Global vs. Sur Global),
disciplinas (ciencias duras, educación, humanidades),
formatos (artículos, informes técnicos, materiales didácticos, preprints).
Esto permitiría mapear con mayor precisión cómo opera la legitimación algorítmica en distintos campos del conocimiento.
b) Análisis longitudinal del sesgo
Evaluar si este sesgo se mantiene, se intensifica o se atenúa a lo largo del tiempo, especialmente a medida que los modelos son reentrenados o ajustados con nuevas políticas de seguridad y ética.
c) Interacción humano–IA y toma de decisiones
Investigar cómo los juicios emitidos por los LLM influyen en decisiones humanas reales: selección de bibliografía, evaluación de trabajos, confianza epistémica, diseño curricular. El foco no estaría solo en el algoritmo, sino en el sistema socio-técnico completo.
d) Cruce con teorías de justicia epistémica
Profundizar el diálogo entre estudios de IA y epistemología social, explorando cómo conceptos como injusticia testimonial, injusticia hermenéutica y autoridad simbólica se reconfiguran en entornos algorítmicos.
9.3. Líneas de acción pedagógica y curricular
Desde una perspectiva educativa —pedagógica-andragógica— este trabajo sugiere oportunidades concretas de intervención:
a) Diseño de experiencias formativas críticas
Convertir este tipo de experimentos en actividades de aula o talleres docentes, donde los estudiantes comparen outputs de IA con contenidos idénticos y reflexionen sobre los criterios implícitos de evaluación.
b) Alfabetización algorítmica situada
Superar enfoques instrumentales de competencias digitales e incorporar módulos específicos sobre cómo los algoritmos producen jerarquías de información, legitimación y autoridad.
c) Evaluación formativa consciente de sesgos
Revisar críticamente el uso de IA como apoyo en evaluación académica, explicitando que ningún output algorítmico sustituye el juicio profesional ni la deliberación pedagógica.
9.4. Líneas de acción tecnológica y de gobernanza
Finalmente, este estudio no busca deslegitimar la IA, sino orientar su desarrollo responsable. Desde esa lógica propositiva, se plantean acciones posibles:
a) Auditorías de legitimación epistémica
Incorporar pruebas A/B sistemáticas en el diseño de modelos para detectar penalizaciones por fuente, formato o autoría, no solo por variables demográficas.
b) Explicabilidad orientada al usuario
Desarrollar mecanismos simples que informen al usuario cuando factores contextuales (como la fuente) influyen en la evaluación del contenido.
c) Gobernanza participativa
Incluir a educadores, investigadores y comunidades académicas no institucionalizadas en la discusión sobre criterios de calidad incorporados en los sistemas de IA.
9.5. Cierre propositivo
Lejos de una postura denunciante, este trabajo se inscribe en una lógica de diseño crítico: hacer visible el fenómeno para poder intervenirlo. La inteligencia artificial no es un destino inevitable, sino una construcción social y técnica en permanente ajuste. Reconocer que los algoritmos pueden automatizar jerarquías epistémicas es el primer paso para rediseñarlos con mayor conciencia, pluralismo y responsabilidad.
En última instancia, el desafío no es lograr máquinas “neutrales” —una ilusión técnica y filosófica—, sino sistemas reflexivos, capaces de convivir con la diversidad del conocimiento humano sin clausurarla. Ahí es donde la educación, la ética y la investigación aplicada pueden y deben encontrarse.